
Decode the Buzzword: Why Harness Engineering Matters Now
back to All
Harness engineering has become the latest buzzword in the AI engineering lexicon, following prompt engineering and context engineering before it.
The pattern behind this progression is increasingly clear: as foundation model capabilities mature, the real ceiling on agent performance is no longer the model itself. It’s the entire system built around it. For model companies especially, whoever gets the harness right first captures the highest-quality execution trajectories, and whoever keeps capturing those trajectories builds the stronger data flywheel.
DeepMind Staff Engineer Philipp Schmid put it bluntly:
“The Harness is the Dataset. Competitive advantage is now the trajectories your harness captures.”
We recently did a deep dive into this concept, drawing on practices from teams at Anthropic, OpenAI, and Google, as well as conversations with top practitioners in agentic engineering. Here are the key frameworks and takeaways.
Why Harness Engineering Is Having Its Moment
The word “harness” comes from equestrian gear. The analogy is apt: a model is like a powerful but unpredictable horse. Humans use a harness to direct the horse’s behavior and control its path. In the AI context, a harness is the surrounding system that channels model capabilities.
Looking at the timeline, AI engineering methodology has gone through three distinct evolutions:
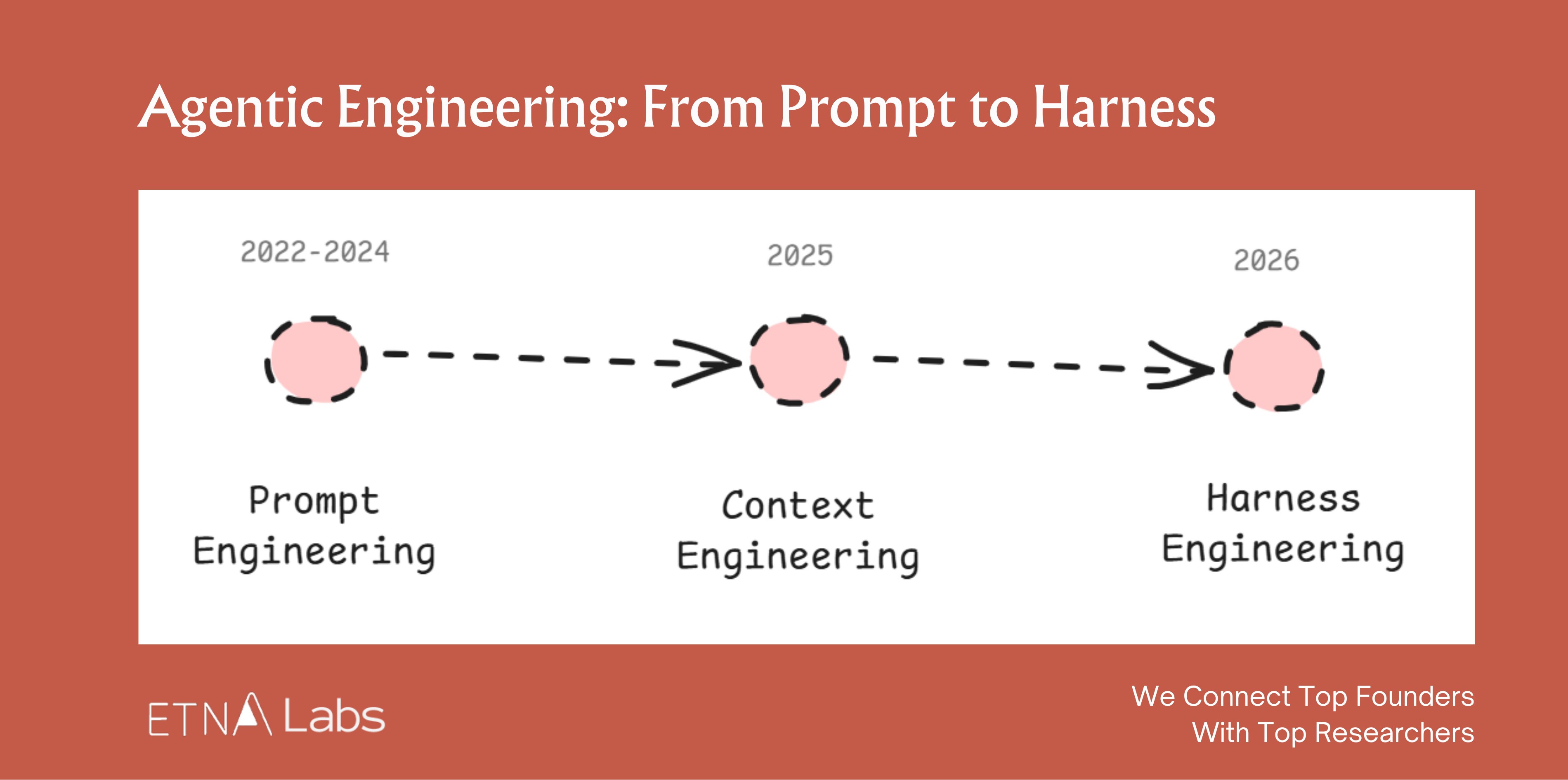
Prompt engineering (2022–2024) focused on how to express a request. The craft was in shaping single-turn instructions: adding personas, context, goals, examples, all to get the model to reliably produce the desired output.
Context engineering (2025) focused on how to provide the right information. As tasks grew more complex, AI needed access to all relevant background material within a limited context window. The discipline shifted to retrieval, compression, and organization of context.
Harness engineering (2026) focuses on how to build the system. Think of the “system” as everything around the model that makes it actually useful: the runtime environment, tool interfaces, memory systems, evaluation and rollback mechanisms. It’s a complete runtime and control system that lets an agent operate reliably and safely.
If we had to write a definition: Agent = LLM + Harness.
The model decides what to do. The harness decides what the model can see, what tools it can use, and what happens when things go wrong.
The shared logic across all three evolutions: once model capability passes a threshold, the bottleneck migrates outward.
A landmark moment in this migration was the release of Claude Opus 4.5 in November 2025. It signaled that agentic capabilities had reached a tipping point where “using a model well” started to matter more than “making a model better.” The bottleneck had shifted from raw intelligence to the system layer.
Anatomy of a Harness
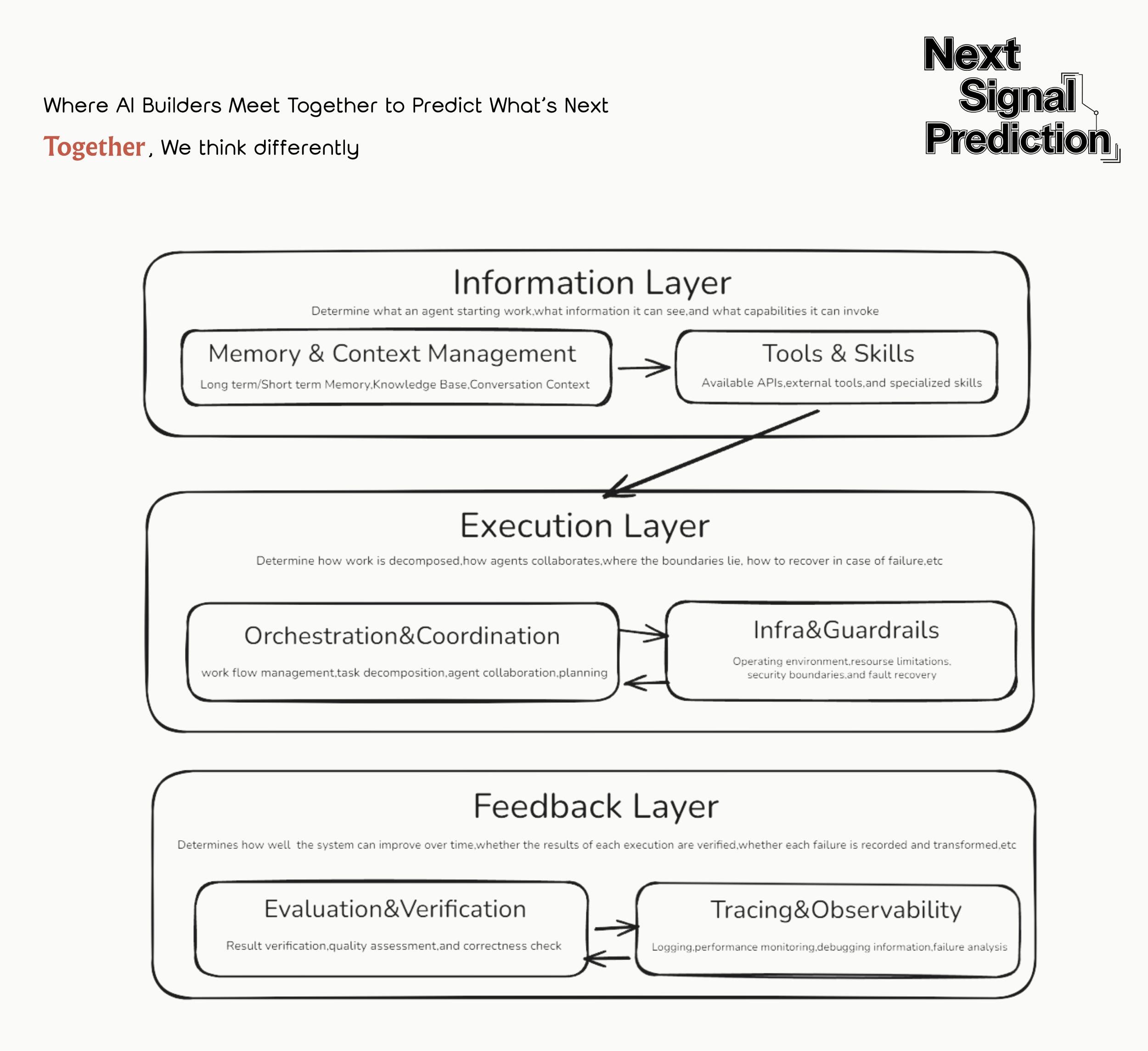
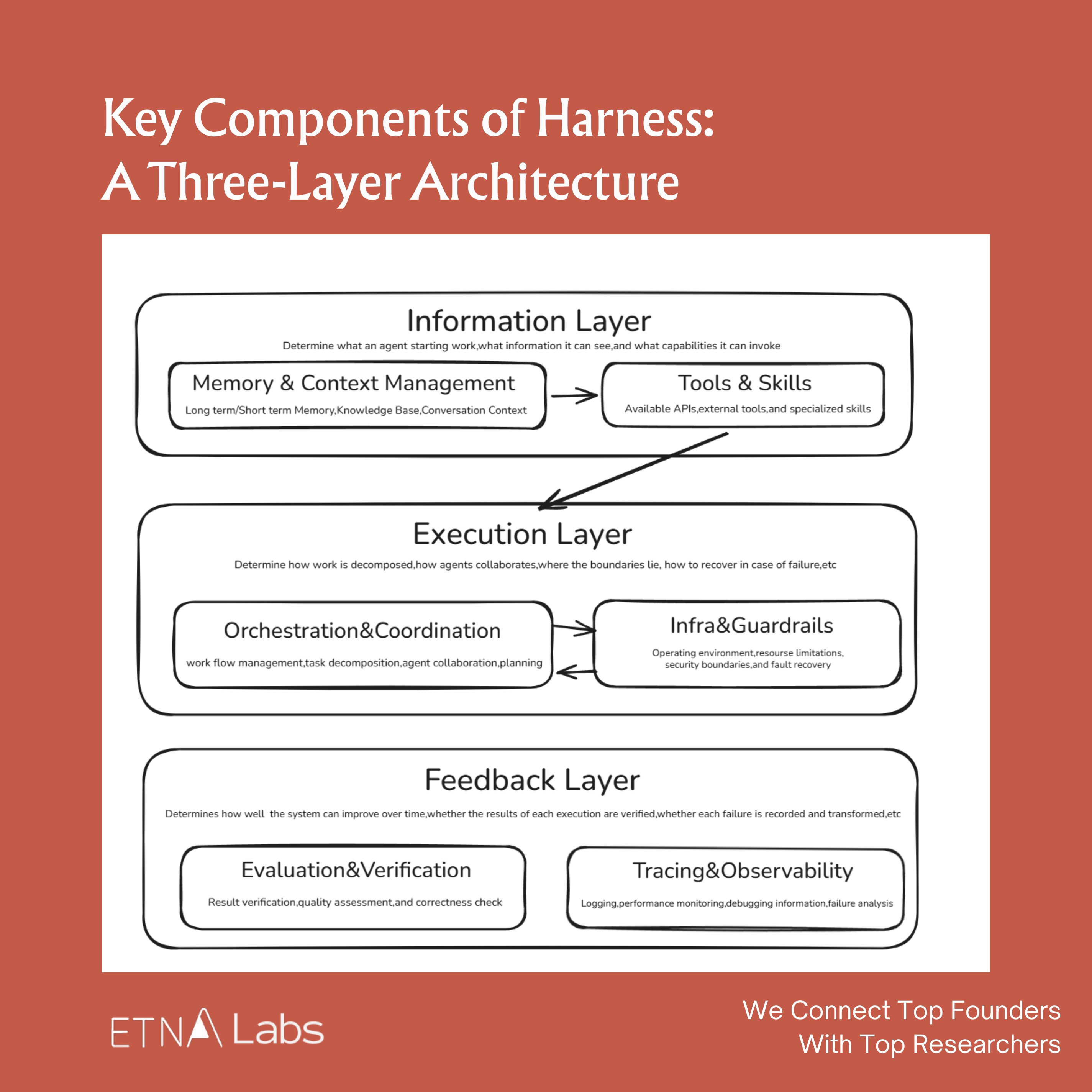
There’s no absolute consensus on what constitutes a harness, but across the different implementations we’ve seen, we group it into six components:
1. Memory & Context Management :This layer answers: “What information should the agent see right now?” Common approaches include context trimming, compression, on-demand retrieval, and external state stores.
2. Tools & Skills :The action layer. Tools provide callable external capabilities; skills provide reusable task methods.
3. Orchestration & Coordination :The workflow layer that choreographs multi-agent task flows, deciding when to plan, when to execute, and when to hand off, so complex tasks can be decomposed and driven to completion.
4. Infra & Guardrails : The runtime layer providing boundary conditions: sandboxing, permission controls, failure recovery, and safety rails to ensure agents operate securely in real environments.
5. Evaluation & Verification : For many complex tasks, the final quality is determined not by the first-pass generation but by whether a verification loop exists. Many harnesses include built-in testing, checking, and feedback mechanisms so agents can validate their own work and self-correct.
6. Tracing & Observability : The transparency layer that reconstructs agent behavior, providing execution trajectories, logs, monitoring, and cost analysis. A system is only debuggable, optimizable, and manageable when its processes are visible.
From a task-completion perspective, these six components map to a clear pipeline: prepare information, then drive execution, then review results. They can be further grouped into three layers: the information layer, the execution layer, and the feedback layer.
Each component looks simple in isolation. But when these small innovations are woven together, something emergent happens: cross-platform presence, proactive conversation initiation, evolving memory. These are capabilities the model alone doesn’t have.
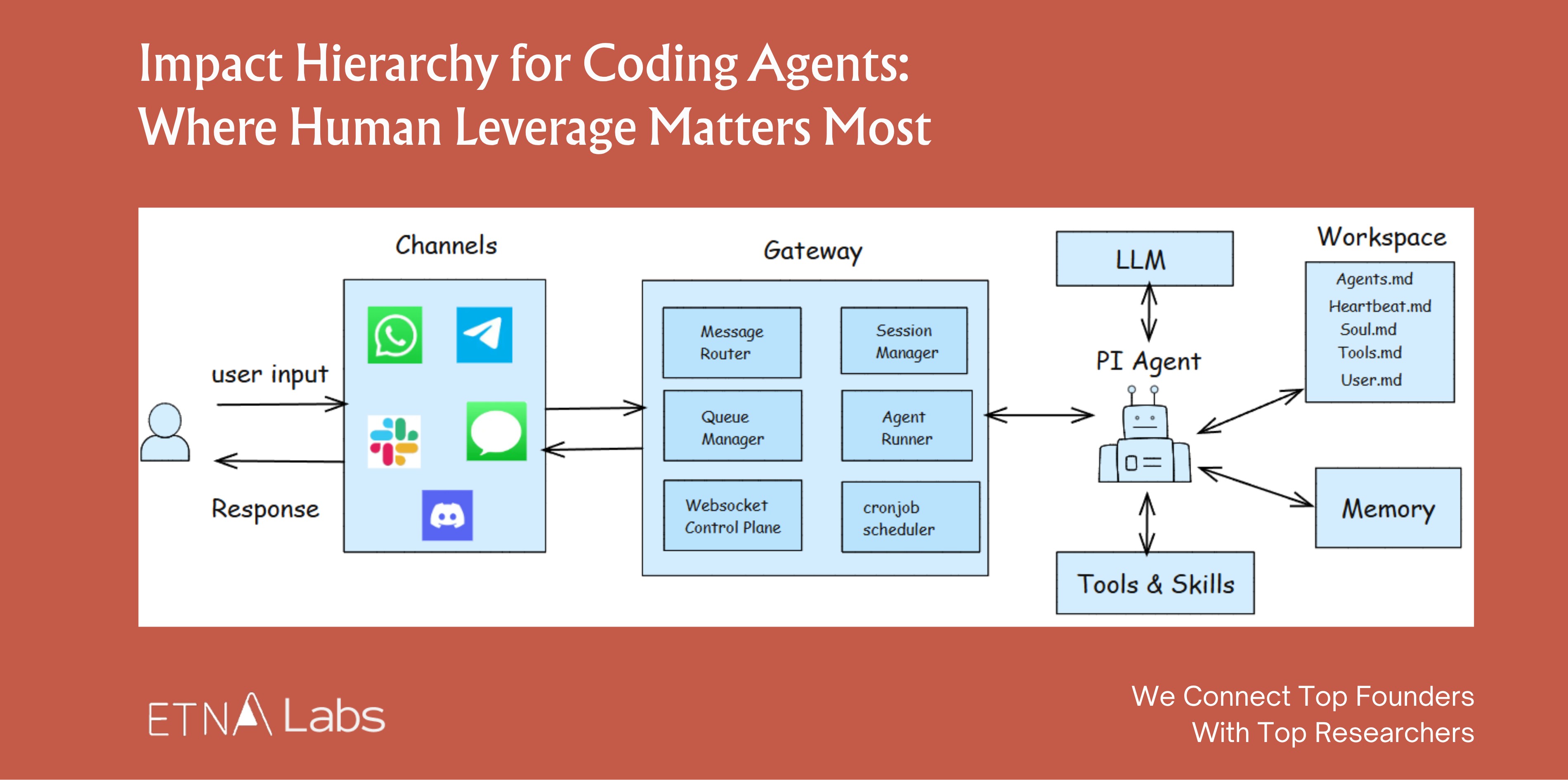
A Concrete example: OpenClaw’s viral success was largely a victory for harness engineering. It didn’t rely on superior model capability. It created an “aha moment” entirely through harness design. Its core engineering highlights:
• A Gateway layer that unifies WhatsApp, Discord, and other messaging platforms, letting the agent show up like a friend in any channel;
• A built-in Skills library providing a rich set of callable capabilities;
• A memory system that lets it accumulate experience and continuously evolve;
• A Heartbeat mechanism that gives the AI “agency,” letting it wake up and initiate actions on its own schedule;
• Soul.md personality files that inject a vivid persona into otherwise cold code.
Design Principles for the Harness
These principles apply not just to agentic engineers but to anyone using Claude Code or Codex as a knowledge worker.
The biggest bottleneck for agents today remains context length limitations, so harness design is fundamentally organized around this constraint. The information, execution, and feedback layers each have distinct design principles:
1. The Information Layer: Preparing the Right Context
The information layer’s job sounds simple: give the agent the information it needs. In practice, this is where things go wrong most easily, and the failure mode is almost always giving too much rather than too little. Models suffer from context decay: as context grows longer, the model doesn’t linearly “know more.” It becomes more susceptible to noise, and attention to critical information points degrades.
The core design principle: precision over completeness.
Trick 1: Progressive Disclosure
Structure information as a “layered loading” system where the model only touches the layer it needs at each stage, rather than front-loading everything into the AI at once.
OpenAI, for example, tried writing one massive AGENTS.md file with every rule included. It didn’t work. Context is a scarce resource; a massive instruction file crowds out the AI’s capacity to focus on what actually matters.
The current best practice is layered disclosure through the file system. Claude Code organizes core information into three tiers:
• Level 1 CLAUDE.md: Only the most critical, most frequently used meta-rules. It’s an entry point that tells the model the project basics and which principles to follow for different task types.
• Level 2 SKILL.md: On-demand capability packs. Only when a specific task appears does the model load the corresponding skill to learn that task’s methodology.
• Level 3 References, supporting files, scripts: At this layer, the model engages with concrete details rather than abstract principles: documentation, worked examples, architecture info, logs, config files, test commands, or raw script output.
Progressive disclosure is fundamentally about controlling the order of information appearance, keeping the model’s attention concentrated on the most critical 1% of information at any given moment.
Trick 2: Fewer, Better Tools
This one is counterintuitive: as model capability improves, its reliance on external tools should decrease, not increase.
An agent’s power comes not from how many wrenches are in its toolbox, but from whether it has a few perfect “universal wrenches” and how effectively it combines them. Overly complex tool sets are a breeding ground for hallucination. A common failure pattern: as the tool set grows, the agent falls into decision paralysis.
Claude Code has roughly 20 tools today. Even so, the team continually reviews whether each one is truly needed and adds new ones very cautiously.
The Vercel team initially equipped their agent with a comprehensive toolkit covering search, code, files, and APIs. Performance was poor. After trimming to only core tools, both speed and reliability improved significantly.
Trick 3: Find the Context Window Sweet Spot
Multiple independent engineering teams have converged on the same finding: once context utilization exceeds a certain threshold, performance starts declining. Stuffing too much history and background into an agent doesn’t make it stronger; it makes it confused.
The exact sweet spot varies by model, context window size, and task type. In the latest needle-in-a-haystack benchmarks, as input token count scales from 256K toward 1M, virtually every major model shows clear degradation.
The best performers (Opus 4.6 family) still maintain around 70% retrieval accuracy at long contexts, while less robust models (GPT-5.4, Gemini 3.1 Pro) drop to 30%.
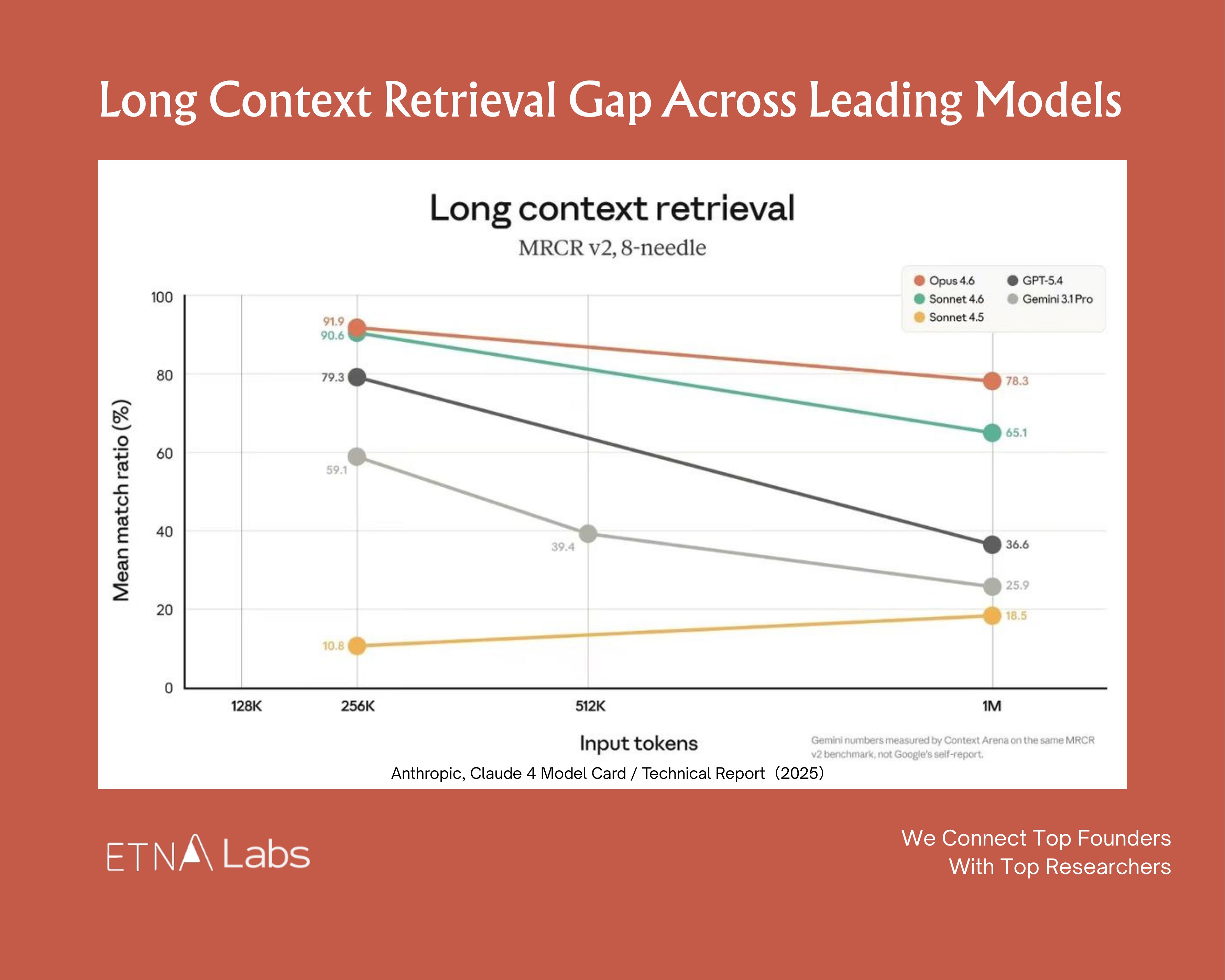
Top engineers compress context aggressively, keeping context window utilization below 60%.
Trick 4: Use Subagents for Context Isolation
When the main agent’s context starts getting heavy, farming out subtasks to independent subagents is a viable approach. Each subagent works in a smaller, cleaner context to complete its own task with less noise interference. Once they produce results, the main agent aggregates and orchestrates.
Boris Cherny, Claude Code’s creator, calls this a “context firewall.” For complex tasks, he directs the main agent to “use subagents,” farming out log review, code inspection, and document search. The main thread handles only scheduling and convergence.
2. The Execution Layer: Giving the Agent a Playbook
If the information layer is about “what information the agent sees,” the execution layer is about “how the agent acts.” The most common problem here is task structure design.
Trick 5: Separate Research, Planning, Execution, and Verification
Across top AI labs, a widely adopted practice is deliberately decomposing a single task chain into four steps: research → plan → execute → verify.
Each phase gets its own session with its own context, rather than expecting everything to happen in one shot.
The logic: the agent has limited capacity. Four phases in one context creates unnecessary pollution. Better to spend more compute on cleaner, crisper tasks.
Instead of issuing “Build me an identity verification system,” a better approach:Decide on the approach. (One workflow in the Claude Code team: have one Claude write the plan, then launch a second Claude to review it from a staff engineer’s perspective.)
Boris Cherny’s CLAUDE.md includes an explicit rule:
Enter plan mode for ANY non-trivial task (3+ steps or architectural decisions). If something goes sideways, STOP and re-plan immediately — don’t keep pushing.
In January 2026, he added another refinement: after the user accepts a plan, Claude Code automatically clears context, letting the execution phase start from a clean slate.
Separating research and execution actually ensures the plan gets implemented more accurately.
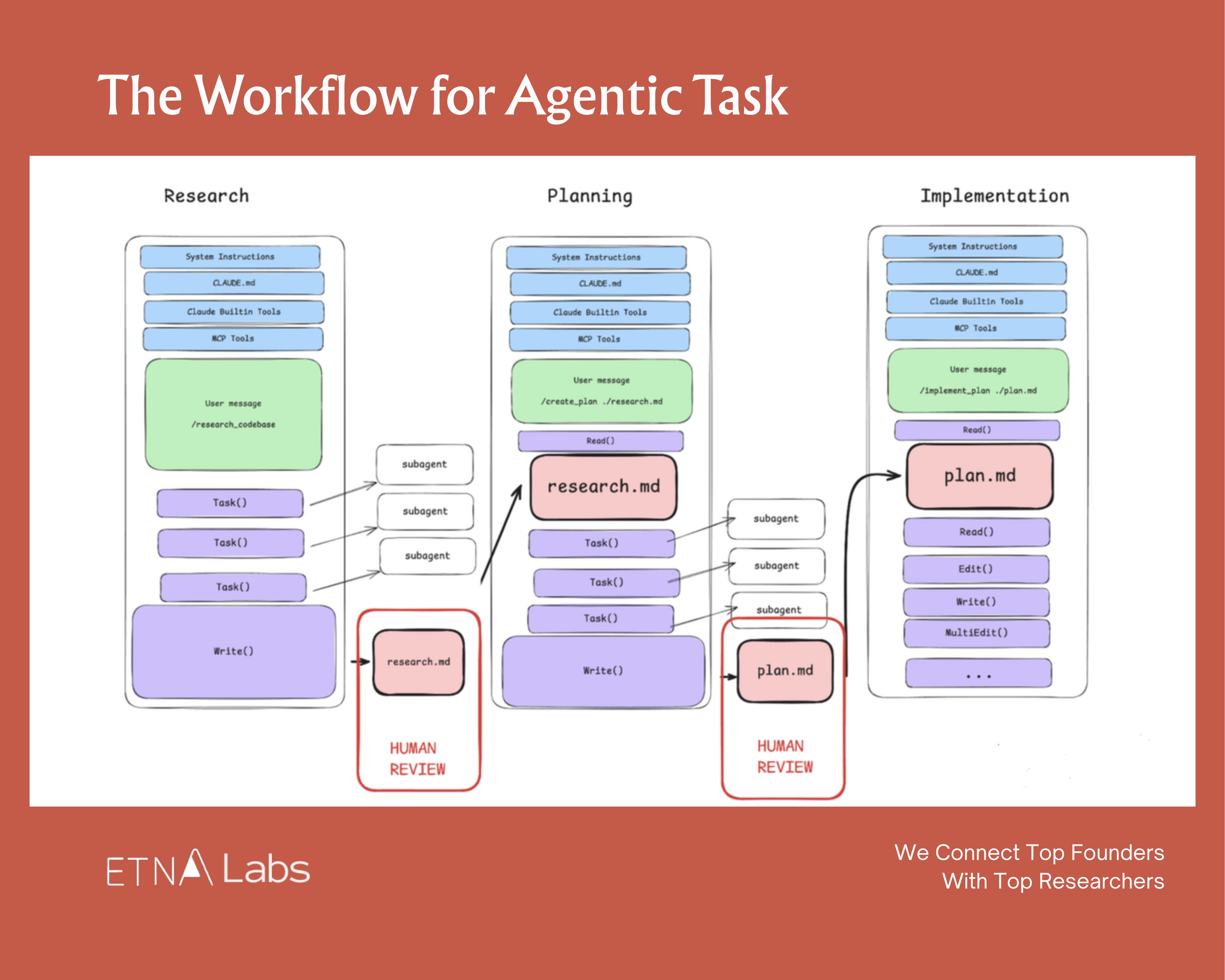
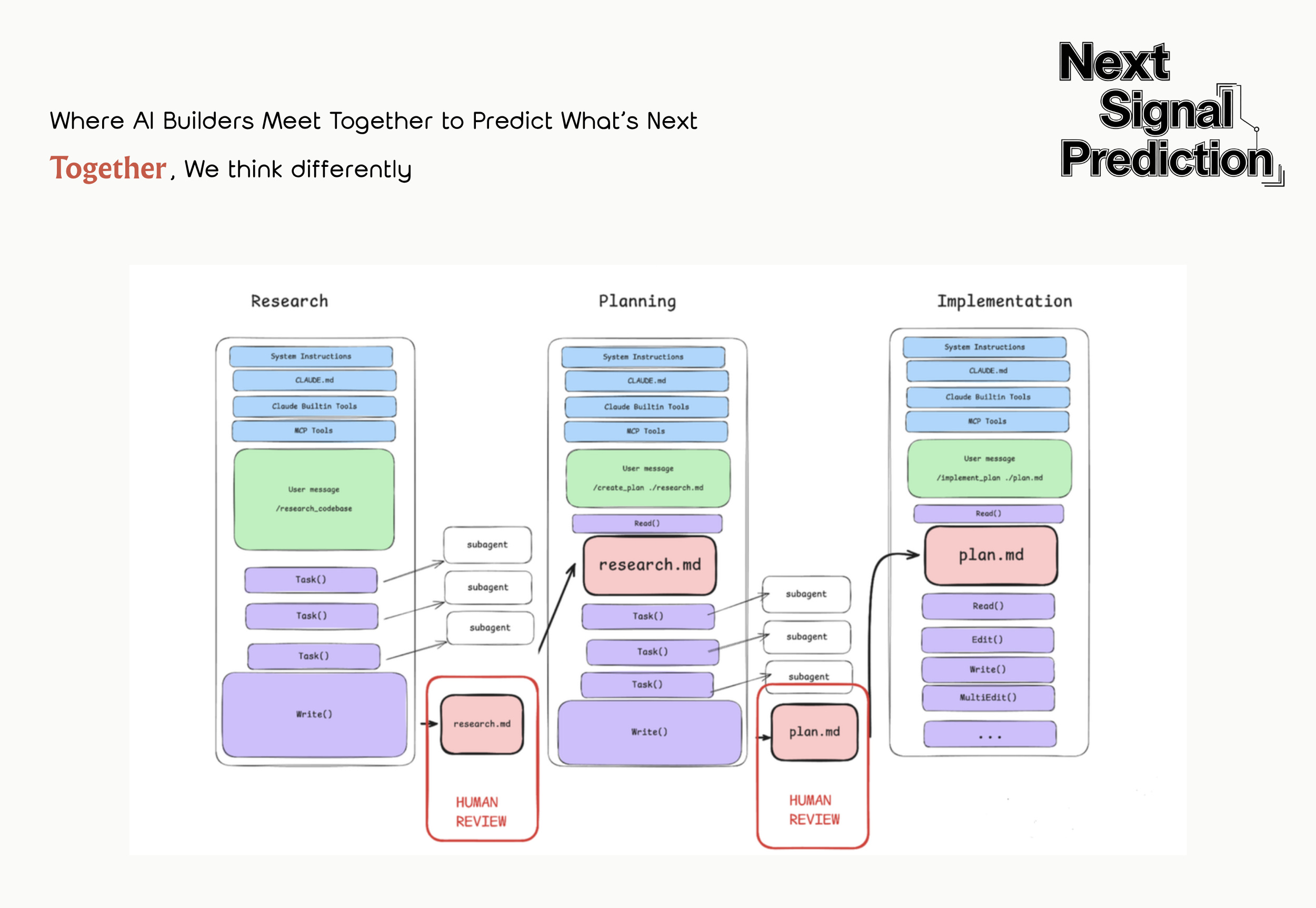
Trick 6: Human Leverage Belongs in Planning, Not Review
Most people instinctively focus their energy on reviewing outputs rather than designing the upfront plan. In reality, effort should shift forward to the research and planning phases, where leverage is highest. A bad line of code affects one line. A bad line of planning spawns hundreds of bad lines of code.
The further upstream the intervention, the greater the impact per unit of time.
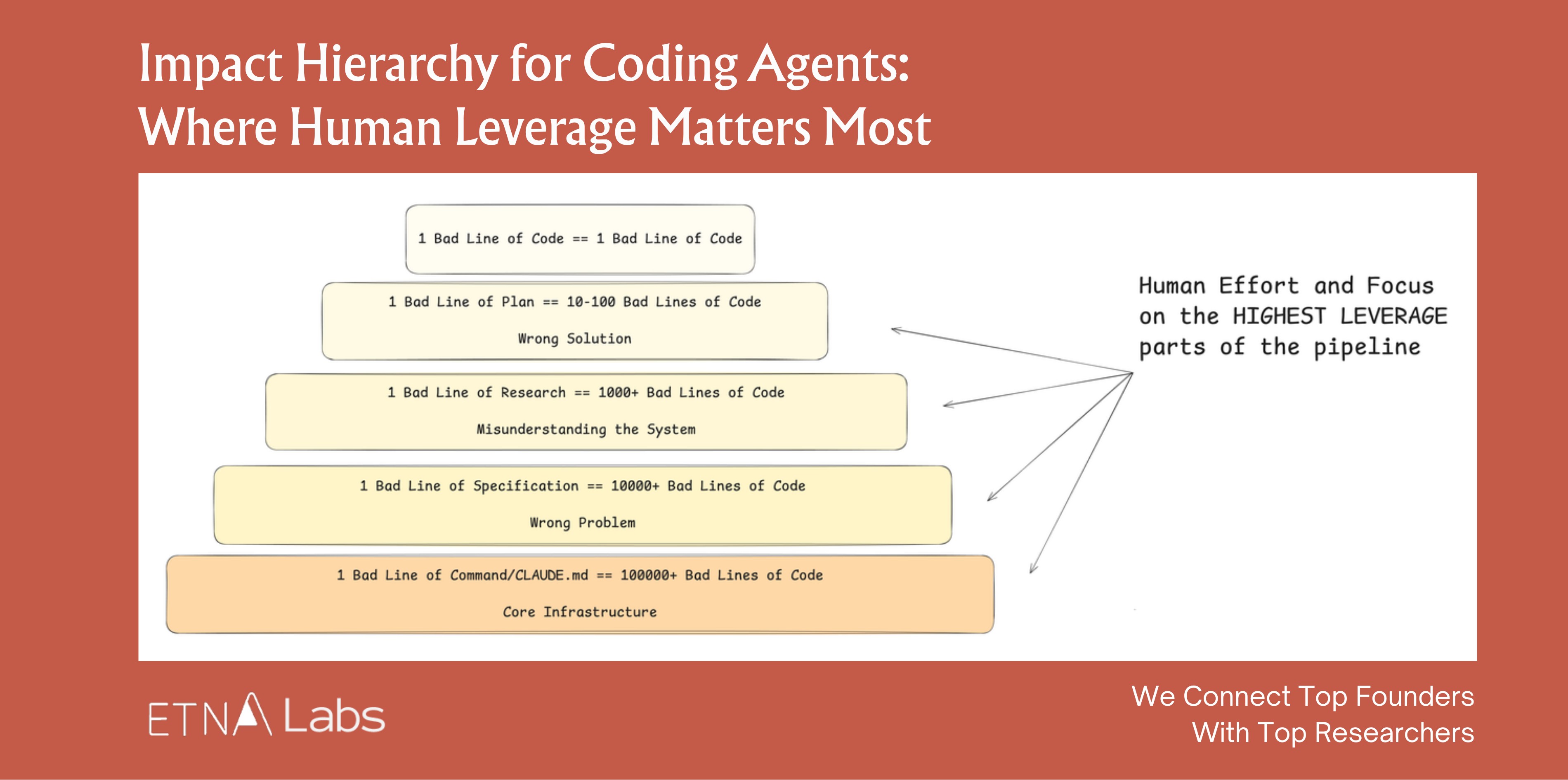
3. The Feedback Layer: The Agent’s Compound Interest Flywheel
The first two layers determine what an agent can do. The feedback layer determines how well the system improves over time. This is the layer most easily overlooked and the one with the strongest compounding effects.
Mitchell Hashimoto wrote:
Anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again.
This represents an engineering discipline: every failure is not an endpoint, but an opportunity to permanently improve the system. The Claude Code team maintains a shared CLAUDE.md with the same principle: whenever Claude makes a mistake, capture that lesson so it doesn’t repeat the same error.
Trick 7: Build Feedback Loops
The highest-ROI investment in harness engineering is building automated feedback and calibration mechanisms for the agent.
Boris Cherny shared that giving Claude effective verification means typically improves final output quality 2–3x. His methods:
• After task completion, prompting another agent to verify results, or enabling stop hooks for self-validation;
• Using the ralph-wiggum plugin to turn the entire flow into “auto-iterate mode,” letting Claude keep doing, keep verifying, keep going until completion criteria are met;
• Having Claude open a browser, test the UI, and iterate until the UX passes.
Karpathy’s autoresearch concept pushes this further. The point isn’t getting AI to produce the best answer in one shot. It’s about getting the AI into a controlled loop: propose an idea → run the experiment → observe results → keep effective strategies, prune dead branches → reflect and propose different improvements → repeat.
The Model-Harness Relationship
The question everyone asks about harness: Will models eat the scaffolding?
Products like Claude Code and Codex are already evidence that model companies are competing not just at the model layer, but on the entire “model + harness” package.
Training Is Deployment
Agent capability ceilings are increasingly determined by environment quality, not just the model itself. In the agentic RL training paradigm, model and harness are not designed separately from the start.
Agentic RL is fundamentally different from standard chatbot RLHF. It involves multi-turn, long-horizon tasks with tool use (a single rollout might invoke tools hundreds of times), a massive action space, extremely sparse reward signals, and heavy dependence on real-environment feedback like test pass rates, code execution results, and linter output.
When Cursor trained Composer 1.5, they used nearly the same production coding environment that serves real users. They spun up hundreds of thousands of sandboxes in parallel, letting the model iterate: what to search, which files to read, how much code to change, when to stop and verify.
Windsurf was explicit when training SWE-1.5:
We believe that the quality of the coding environments in RL tasks is the most important factor for downstream model performance.
Our vision is to co-optimize models and harness: we repeatedly dogfooded the model, noticed issues with the harness, made adjustments to tools and prompts, and then re-trained the model on the updated harness.
Models Are Absorbing Harness Capabilities
Model companies are now optimizing “model + harness” as a single unit. Many capabilities that originally required harness enforcement have been internalized by models through post-training: tool search, programmatic tool use, compaction/summarization, multi-step tool invocation strategies.
The cycle typically works like this:
• Model teams and community users explore the frontier, discovering which methods actually work
• Training teams take these patterns and incorporate them into post-training
• Models begin internalizing these capabilities; what once required harness enforcement starts becoming native model behavior
• New harness designs emerge to support new model capabilities
• The cycle repeats
Boris Cherny has noted that Claude Code’s harness is being continuously rewritten, with any given line of code having a shelf life of perhaps two months.
Harness as Dataset
Philipp Schmid’s framing bears repeating: the truly valuable data now isn’t just static corpora. It’s the execution trajectories agents generate during real workflows: what information they saw, what tools they used, what decisions they made, which steps went wrong, what feedback made them improve.
In this framing, the harness is no longer mere scaffolding outside the model. It’s the soil from which model capability grows. The quality of that soil will, to a meaningful degree, determine and compound the growth of intelligence.
The current market situation: even though model capability between the two leading labs has largely converged, most people are still using Claude Code. An interesting divergence is emerging: leading model companies are building end-to-end harnesses, while application companies are increasingly training their own models on their own harness and business data.
This competitive dynamic may become one of the most interesting storylines in AI over the next few years.
Where the Startups Are
As harness importance grows, we see emerging startup opportunities across each layer. Here are some representative companies with strong momentum, all of which have recently raised significant rounds from top-tier firms.
Information Layer
One of the biggest bottlenecks in enterprise AI today: agents lack sufficient background information. How to extract the scattered, tacit knowledge trapped inside an enterprise and make it agent-accessible is a significant startup opportunity.
- Edra positions itself as “Context for Agents at Scale.” It automatically ingests tickets, logs, emails, and chat histories, then runs thousands of agents in parallel to reverse-engineer how a company actually operates, compiling reusable agent playbooks. In March 2026, Edra closed a ~$30M Series A led by Sequoia.

Execution Layer
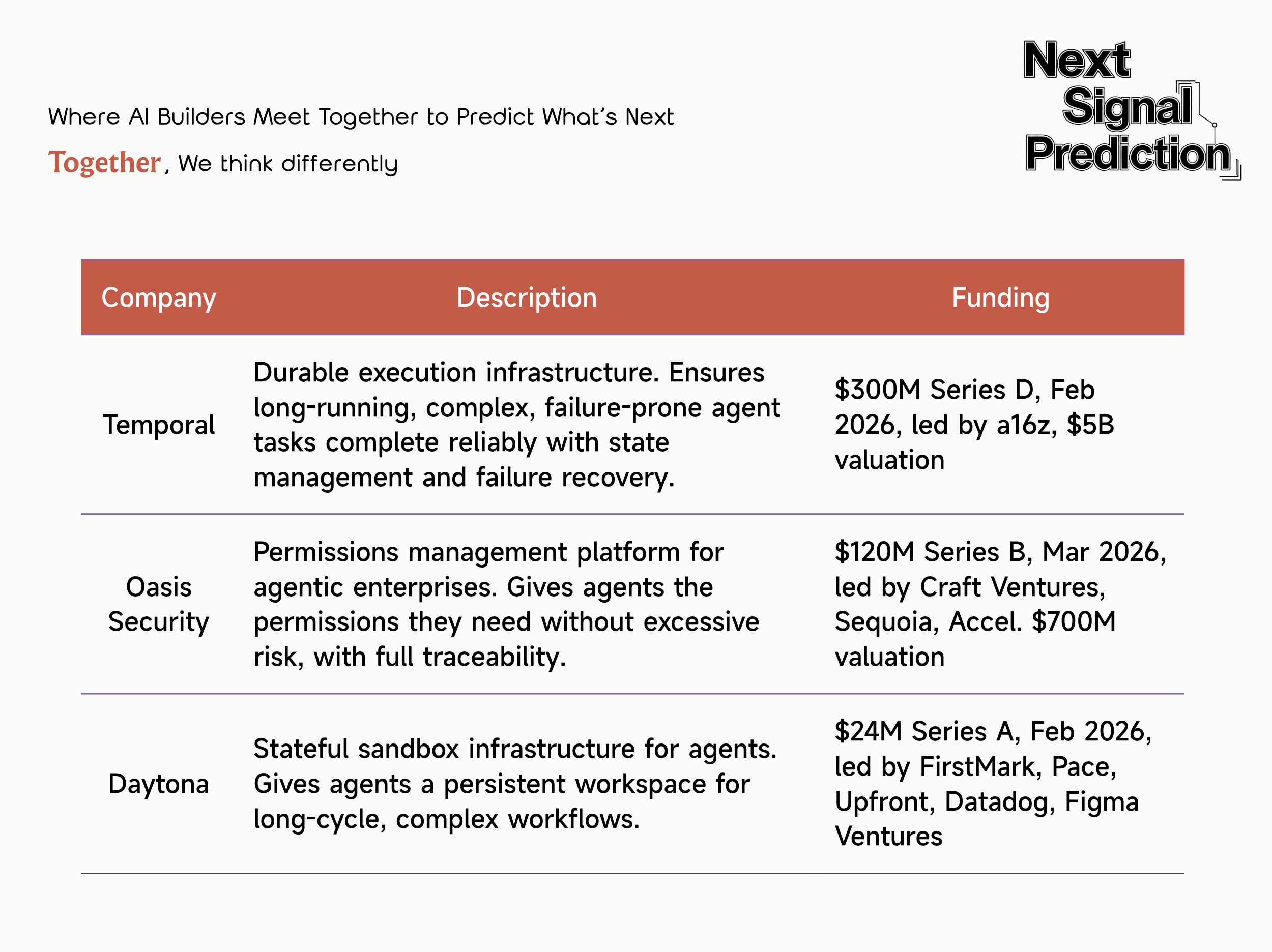
- Temporal provides the underlying infrastructure for durable execution: letting very long, complex, failure-prone tasks run to completion reliably. Clients include OpenAI, Replit, Netflix, Stripe, Datadog, Snapchat, and JPMorgan. In February 2026, Temporal closed a $300M Series D led by a16z at a $5B valuation.
- Oasis Security builds permission management for agentic enterprises. As AI agents increasingly access systems and call data, Oasis helps companies track digital identities, enforce least-privilege access, and maintain auditability. In March 2026, Oasis closed a $120M Series B led by Craft Ventures, Sequoia, and Accel at a $700M valuation.
- Daytona builds sandbox infrastructure for agents. Unlike E2B (a safe execution box), Daytona is more like “giving the agent a long-term-use computer.” In February 2026, Daytona closed a $24M Series A led by FirstMark, with Pace, Upfront, Datadog, and Figma Ventures
Feedback Layer
Evaluation and observability is the layer we’re most optimistic about.
Enterprises need an independent quality control plane; this is an acute pain point today; and once adopted, this layer embeds deeply into AI workflows with high switching costs.
- Braintrust an AI observability and evaluation platform that helps teams see what happens in production (traces), judge quality (human or LLM scoring), and continuously optimize (distilling production issues into test sets). In February 2026, Braintrust closed an $80M Series B led by ICONIQ, with a16z, Greylock, Elad Gil, and Basecase, at an $800M valuation.

From Harness to Coordination
If you look at prompt engineering, context engineering, and harness engineering together, they trace the growth arc of a junior employee. At first, you can only do simple Q&A. Then you get enough business context to do independent research. Then you get tools, permissions, and feedback mechanisms to decompose tasks, use tools, and even lead a few subagents.
The natural question: what comes next?
Following the human career path analogy, the next stage agents need to reach is coordinating countless agents and human nodes to accomplish complex tasks together.
We might call it Coordination Engineering.
OpenAI’s engineering lead and product designer mentioned in a late-January podcast that they’re actively thinking about multi-agent networks:
“Once you enter a multi-agent world, complexity rises fast. How do you manage all of it? How can users always know what each agent is doing, what actions it’s taken, where the workflow stands, and where they need to step in to authorize or correct?”
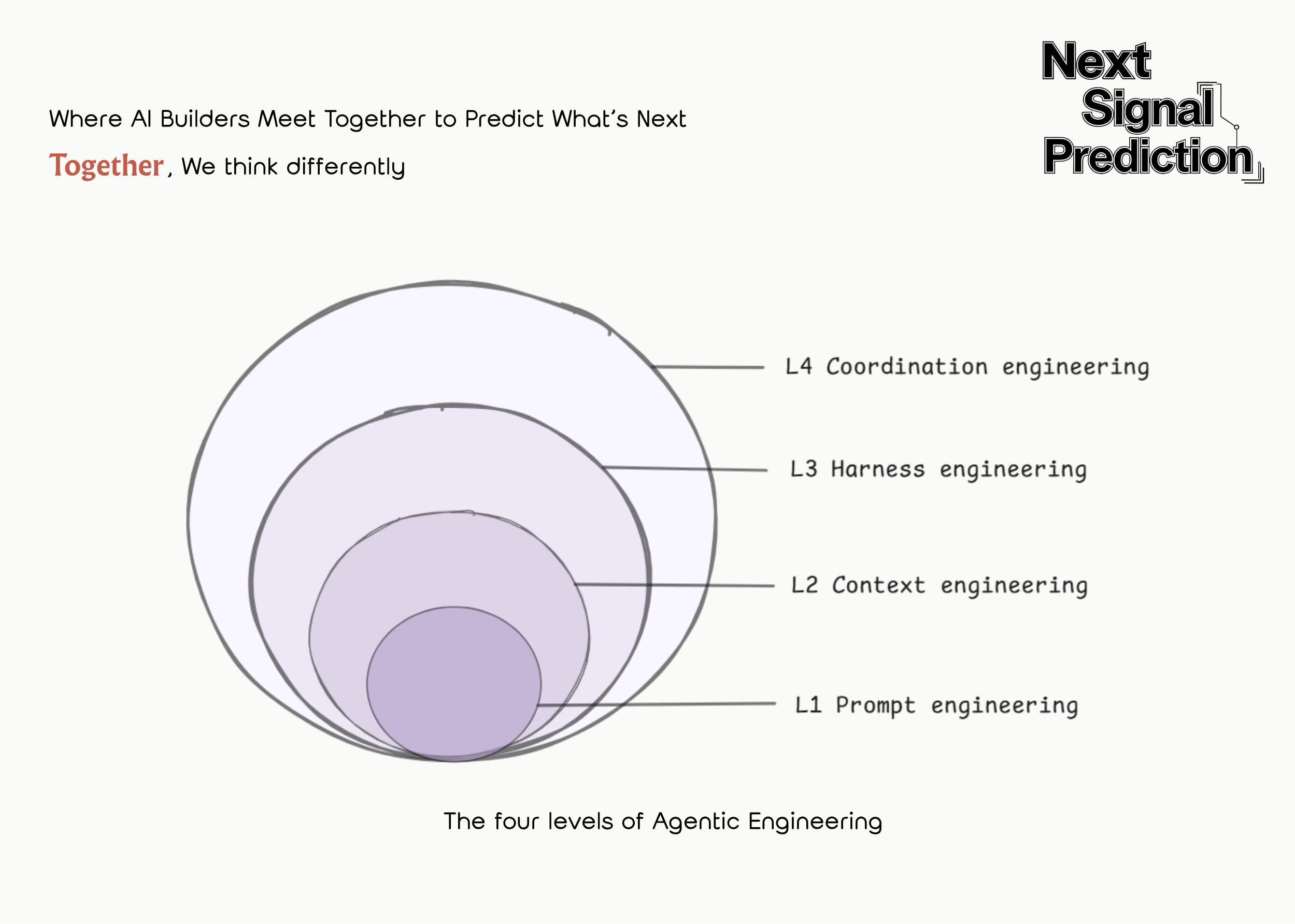
Stacking these four layers together may constitute the ultimate form of agentic engineering. They’re not a replacement relationship but a containment relationship. As the intelligence waterline rises, the “control plane” keeps shifting upward:

• L1 solves response quality
• L2 solves knowledge boundaries
• L3 solves the execution loop
• L4 solves organizational coordination
And if you extrapolate to the logical extreme? Everything reduces to intention engineering. Human value narrows down to “setting the objective function.” AI handles the rest.
When that day comes, what we call knowledge work may turn out to have been a brief detour in human history.
Decode the Buzzword: Why Harness Engineering Matters Now
Back to All
Harness engineering has become the latest buzzword in the AI engineering lexicon, following prompt engineering and context engineering before it.
The pattern behind this progression is increasingly clear: as foundation model capabilities mature, the real ceiling on agent performance is no longer the model itself. It’s the entire system built around it. For model companies especially, whoever gets the harness right first captures the highest-quality execution trajectories, and whoever keeps capturing those trajectories builds the stronger data flywheel.
DeepMind Staff Engineer Philipp Schmid put it bluntly:
“The Harness is the Dataset. Competitive advantage is now the trajectories your harness captures.”
We recently did a deep dive into this concept, drawing on practices from teams at Anthropic, OpenAI, and Google, as well as conversations with top practitioners in agentic engineering. Here are the key frameworks and takeaways.
Why Harness Engineering Is Having Its Moment
The word “harness” comes from equestrian gear. The analogy is apt: a model is like a powerful but unpredictable horse. Humans use a harness to direct the horse’s behavior and control its path. In the AI context, a harness is the surrounding system that channels model capabilities.
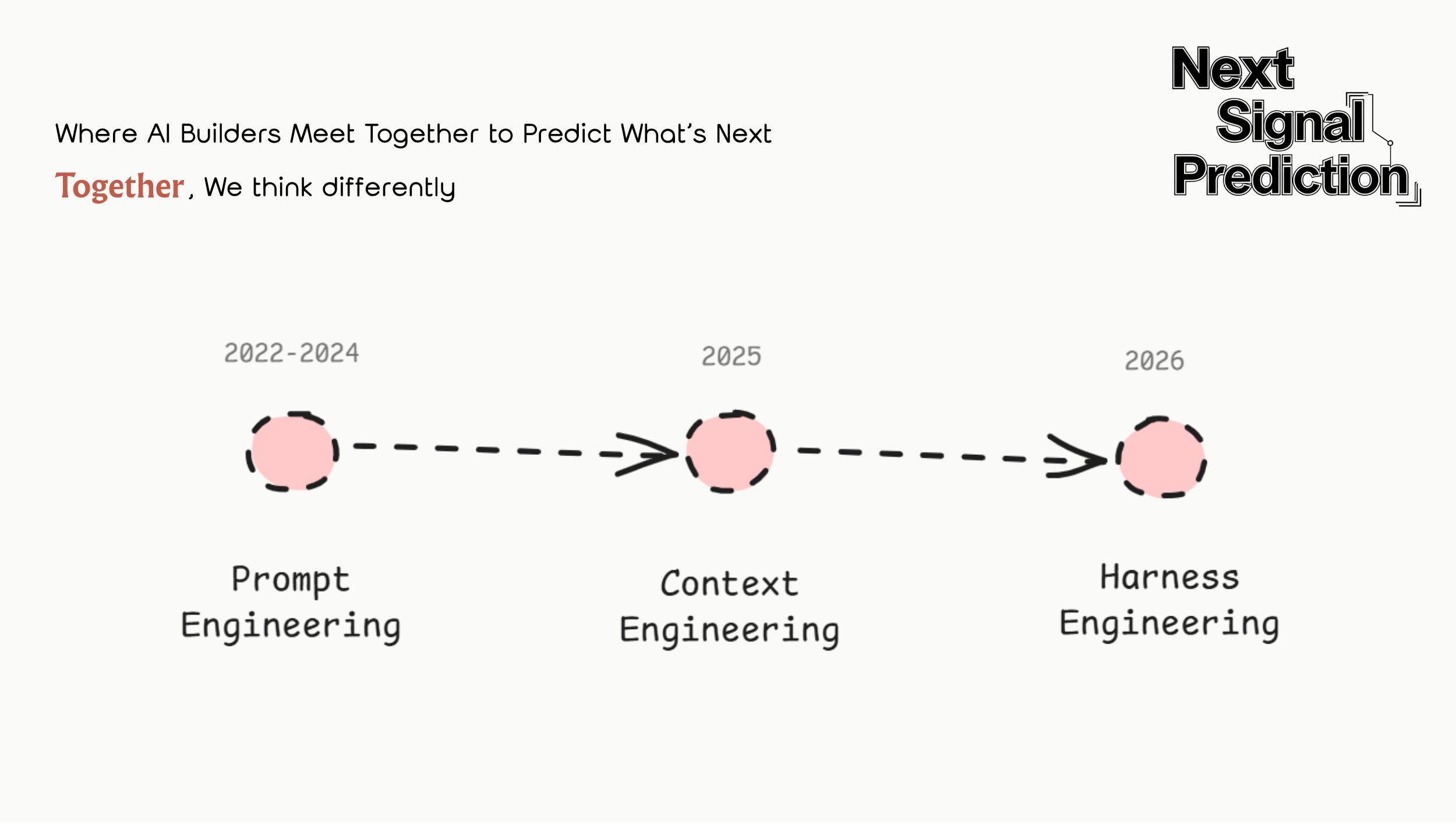
Looking at the timeline, AI engineering methodology has gone through three distinct evolutions:
Prompt engineering (2022–2024) focused on how to express a request. The craft was in shaping single-turn instructions: adding personas, context, goals, examples, all to get the model to reliably produce the desired output.
Context engineering (2025) focused on how to provide the right information. As tasks grew more complex, AI needed access to all relevant background material within a limited context window. The discipline shifted to retrieval, compression, and organization of context.
Harness engineering (2026) focuses on how to build the system. Think of the “system” as everything around the model that makes it actually useful: the runtime environment, tool interfaces, memory systems, evaluation and rollback mechanisms. It’s a complete runtime and control system that lets an agent operate reliably and safely.
If we had to write a definition: Agent = LLM + Harness.
The model decides what to do. The harness decides what the model can see, what tools it can use, and what happens when things go wrong.
The shared logic across all three evolutions: once model capability passes a threshold, the bottleneck migrates outward.
A landmark moment in this migration was the release of Claude Opus 4.5 in November 2025. It signaled that agentic capabilities had reached a tipping point where “using a model well” started to matter more than “making a model better.” The bottleneck had shifted from raw intelligence to the system layer.
Anatomy of a Harness
There’s no absolute consensus on what constitutes a harness, but across the different implementations we’ve seen, we group it into six components:
1. Memory & Context Management :This layer answers: “What information should the agent see right now?” Common approaches include context trimming, compression, on-demand retrieval, and external state stores.
2. Tools & Skills :The action layer. Tools provide callable external capabilities; skills provide reusable task methods.
3. Orchestration & Coordination :The workflow layer that choreographs multi-agent task flows, deciding when to plan, when to execute, and when to hand off, so complex tasks can be decomposed and driven to completion.
4. Infra & Guardrails : The runtime layer providing boundary conditions: sandboxing, permission controls, failure recovery, and safety rails to ensure agents operate securely in real environments.
5. Evaluation & Verification : For many complex tasks, the final quality is determined not by the first-pass generation but by whether a verification loop exists. Many harnesses include built-in testing, checking, and feedback mechanisms so agents can validate their own work and self-correct.
6. Tracing & Observability : The transparency layer that reconstructs agent behavior, providing execution trajectories, logs, monitoring, and cost analysis. A system is only debuggable, optimizable, and manageable when its processes are visible.
From a task-completion perspective, these six components map to a clear pipeline: prepare information, then drive execution, then review results. They can be further grouped into three layers: the information layer, the execution layer, and the feedback layer.
Each component looks simple in isolation. But when these small innovations are woven together, something emergent happens: cross-platform presence, proactive conversation initiation, evolving memory. These are capabilities the model alone doesn’t have.
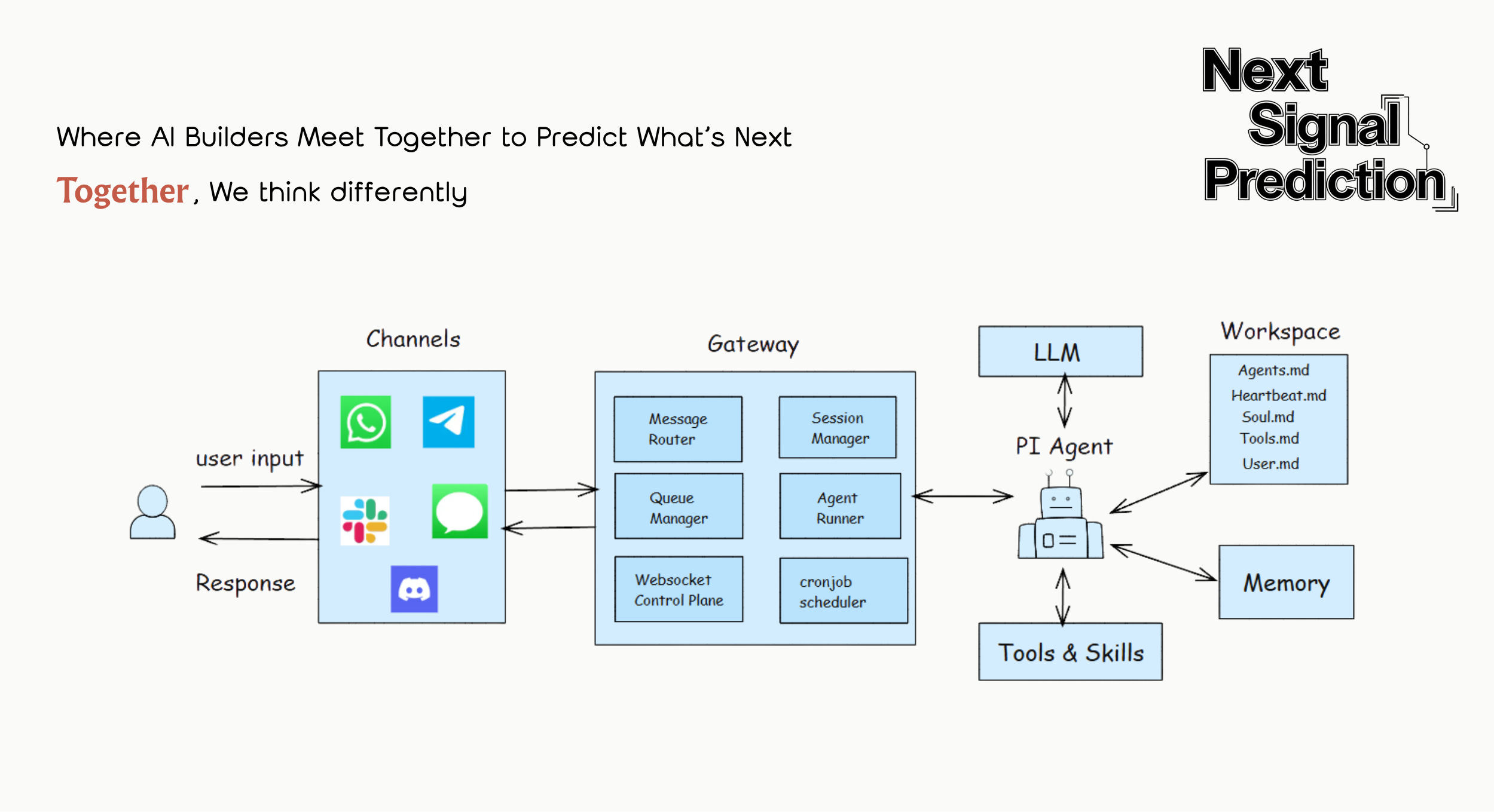
A Concrete example: OpenClaw’s viral success was largely a victory for harness engineering. It didn’t rely on superior model capability. It created an “aha moment” entirely through harness design. Its core engineering highlights:
• A Gateway layer that unifies WhatsApp, Discord, and other messaging platforms, letting the agent show up like a friend in any channel;
• A built-in Skills library providing a rich set of callable capabilities;
• A memory system that lets it accumulate experience and continuously evolve;
• A Heartbeat mechanism that gives the AI “agency,” letting it wake up and initiate actions on its own schedule;
• Soul.md personality files that inject a vivid persona into otherwise cold code.
Design Principles for the Harness
These principles apply not just to agentic engineers but to anyone using Claude Code or Codex as a knowledge worker.
The biggest bottleneck for agents today remains context length limitations, so harness design is fundamentally organized around this constraint. The information, execution, and feedback layers each have distinct design principles:
1. The Information Layer: Preparing the Right Context
The information layer’s job sounds simple: give the agent the information it needs. In practice, this is where things go wrong most easily, and the failure mode is almost always giving too much rather than too little. Models suffer from context decay: as context grows longer, the model doesn’t linearly “know more.” It becomes more susceptible to noise, and attention to critical information points degrades.
The core design principle: precision over completeness.
Trick 1: Progressive Disclosure
Structure information as a “layered loading” system where the model only touches the layer it needs at each stage, rather than front-loading everything into the AI at once.
OpenAI, for example, tried writing one massive AGENTS.md file with every rule included. It didn’t work. Context is a scarce resource; a massive instruction file crowds out the AI’s capacity to focus on what actually matters.
The current best practice is layered disclosure through the file system. Claude Code organizes core information into three tiers:
• Level 1 CLAUDE.md: Only the most critical, most frequently used meta-rules. It’s an entry point that tells the model the project basics and which principles to follow for different task types.
• Level 2 SKILL.md: On-demand capability packs. Only when a specific task appears does the model load the corresponding skill to learn that task’s methodology.
• Level 3 References, supporting files, scripts: At this layer, the model engages with concrete details rather than abstract principles: documentation, worked examples, architecture info, logs, config files, test commands, or raw script output.
Progressive disclosure is fundamentally about controlling the order of information appearance, keeping the model’s attention concentrated on the most critical 1% of information at any given moment.
Trick 2: Fewer, Better Tools
This one is counterintuitive: as model capability improves, its reliance on external tools should decrease, not increase.
An agent’s power comes not from how many wrenches are in its toolbox, but from whether it has a few perfect “universal wrenches” and how effectively it combines them. Overly complex tool sets are a breeding ground for hallucination. A common failure pattern: as the tool set grows, the agent falls into decision paralysis.
Claude Code has roughly 20 tools today. Even so, the team continually reviews whether each one is truly needed and adds new ones very cautiously.
The Vercel team initially equipped their agent with a comprehensive toolkit covering search, code, files, and APIs. Performance was poor. After trimming to only core tools, both speed and reliability improved significantly.
Trick 3: Find the Context Window Sweet Spot
Multiple independent engineering teams have converged on the same finding: once context utilization exceeds a certain threshold, performance starts declining. Stuffing too much history and background into an agent doesn’t make it stronger; it makes it confused.
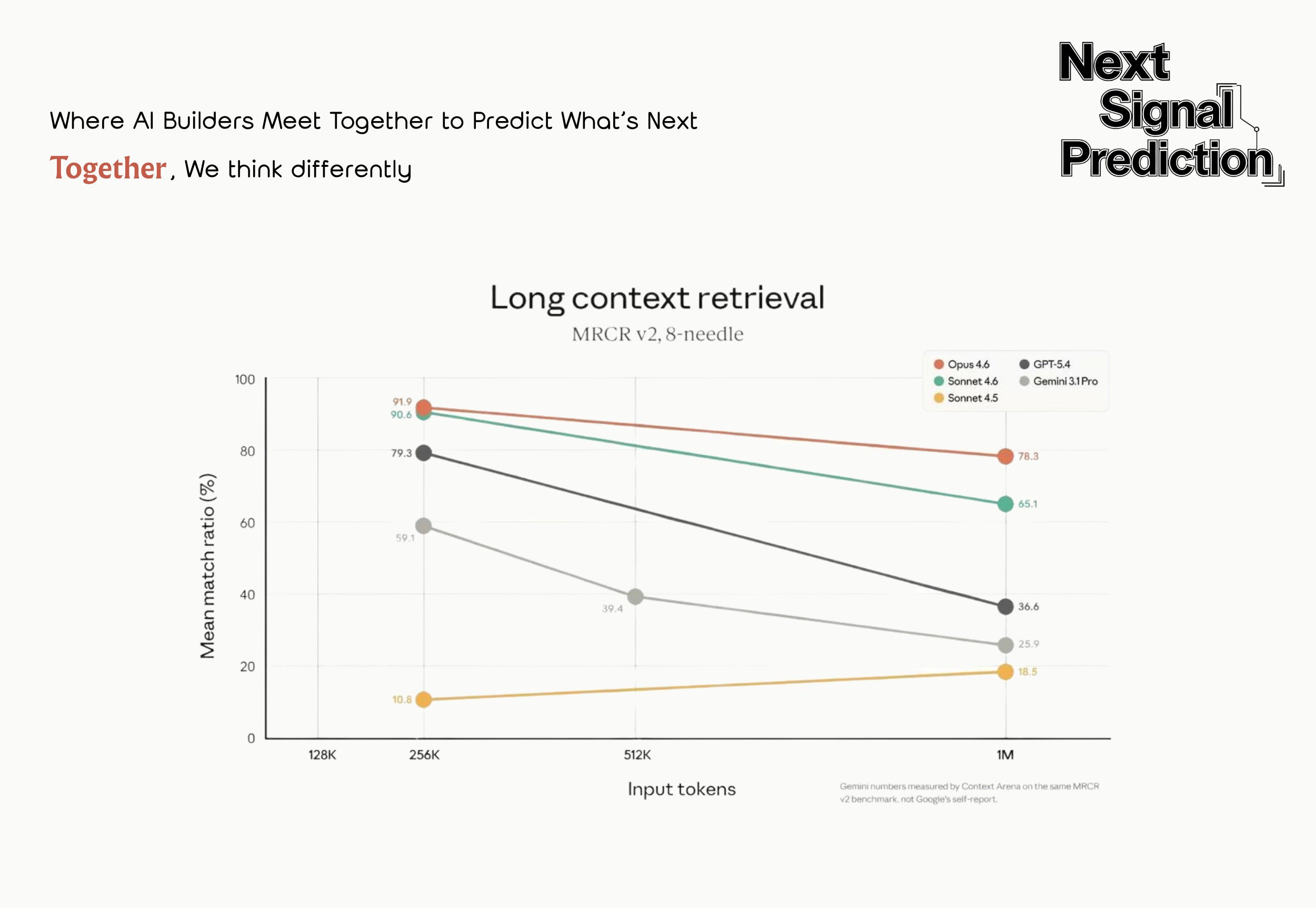
The exact sweet spot varies by model, context window size, and task type. In the latest needle-in-a-haystack benchmarks, as input token count scales from 256K toward 1M, virtually every major model shows clear degradation.
The best performers (Opus 4.6 family) still maintain around 70% retrieval accuracy at long contexts, while less robust models (GPT-5.4, Gemini 3.1 Pro) drop to 30%.
Top engineers compress context aggressively, keeping context window utilization below 60%.
Trick 4: Use Subagents for Context Isolation
When the main agent’s context starts getting heavy, farming out subtasks to independent subagents is a viable approach. Each subagent works in a smaller, cleaner context to complete its own task with less noise interference. Once they produce results, the main agent aggregates and orchestrates.
Boris Cherny, Claude Code’s creator, calls this a “context firewall.” For complex tasks, he directs the main agent to “use subagents,” farming out log review, code inspection, and document search. The main thread handles only scheduling and convergence.
2. The Execution Layer: Giving the Agent a Playbook
If the information layer is about “what information the agent sees,” the execution layer is about “how the agent acts.” The most common problem here is task structure design.
Trick 5: Separate Research, Planning, Execution, and Verification
Across top AI labs, a widely adopted practice is deliberately decomposing a single task chain into four steps: research → plan → execute → verify.
Each phase gets its own session with its own context, rather than expecting everything to happen in one shot.
The logic: the agent has limited capacity. Four phases in one context creates unnecessary pollution. Better to spend more compute on cleaner, crisper tasks.
Instead of issuing “Build me an identity verification system,” a better approach:Decide on the approach. (One workflow in the Claude Code team: have one Claude write the plan, then launch a second Claude to review it from a staff engineer’s perspective.)
Boris Cherny’s CLAUDE.md includes an explicit rule:
Enter plan mode for ANY non-trivial task (3+ steps or architectural decisions). If something goes sideways, STOP and re-plan immediately — don’t keep pushing.
In January 2026, he added another refinement: after the user accepts a plan, Claude Code automatically clears context, letting the execution phase start from a clean slate.
Separating research and execution actually ensures the plan gets implemented more accurately.
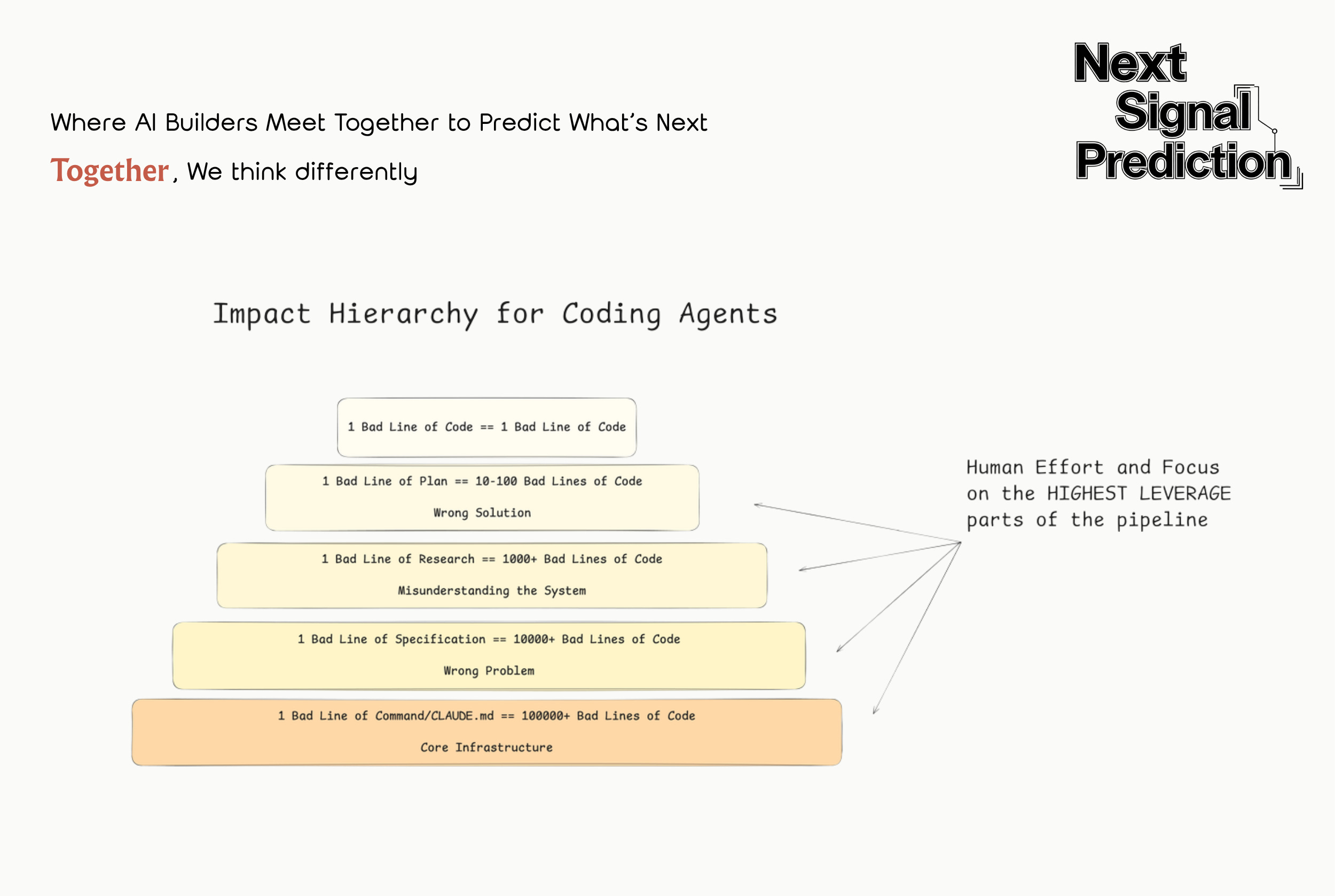
Trick 6: Human Leverage Belongs in Planning, Not Review
Most people instinctively focus their energy on reviewing outputs rather than designing the upfront plan. In reality, effort should shift forward to the research and planning phases, where leverage is highest. A bad line of code affects one line. A bad line of planning spawns hundreds of bad lines of code.
The further upstream the intervention, the greater the impact per unit of time.
3. The Feedback Layer: The Agent’s Compound Interest Flywheel
The first two layers determine what an agent can do. The feedback layer determines how well the system improves over time. This is the layer most easily overlooked and the one with the strongest compounding effects.
Mitchell Hashimoto wrote:
Anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again.
This represents an engineering discipline: every failure is not an endpoint, but an opportunity to permanently improve the system. The Claude Code team maintains a shared CLAUDE.md with the same principle: whenever Claude makes a mistake, capture that lesson so it doesn’t repeat the same error.
Trick 7: Build Feedback Loops
The highest-ROI investment in harness engineering is building automated feedback and calibration mechanisms for the agent.
Boris Cherny shared that giving Claude effective verification means typically improves final output quality 2–3x. His methods:
• After task completion, prompting another agent to verify results, or enabling stop hooks for self-validation;
• Using the ralph-wiggum plugin to turn the entire flow into “auto-iterate mode,” letting Claude keep doing, keep verifying, keep going until completion criteria are met;
• Having Claude open a browser, test the UI, and iterate until the UX passes.
Karpathy’s autoresearch concept pushes this further. The point isn’t getting AI to produce the best answer in one shot. It’s about getting the AI into a controlled loop: propose an idea → run the experiment → observe results → keep effective strategies, prune dead branches → reflect and propose different improvements → repeat.
The Model-Harness Relationship
The question everyone asks about harness: Will models eat the scaffolding?
Products like Claude Code and Codex are already evidence that model companies are competing not just at the model layer, but on the entire “model + harness” package.
Training Is Deployment
Agent capability ceilings are increasingly determined by environment quality, not just the model itself. In the agentic RL training paradigm, model and harness are not designed separately from the start.
Agentic RL is fundamentally different from standard chatbot RLHF. It involves multi-turn, long-horizon tasks with tool use (a single rollout might invoke tools hundreds of times), a massive action space, extremely sparse reward signals, and heavy dependence on real-environment feedback like test pass rates, code execution results, and linter output.
When Cursor trained Composer 1.5, they used nearly the same production coding environment that serves real users. They spun up hundreds of thousands of sandboxes in parallel, letting the model iterate: what to search, which files to read, how much code to change, when to stop and verify.
Windsurf was explicit when training SWE-1.5:
We believe that the quality of the coding environments in RL tasks is the most important factor for downstream model performance.
Our vision is to co-optimize models and harness: we repeatedly dogfooded the model, noticed issues with the harness, made adjustments to tools and prompts, and then re-trained the model on the updated harness.
Models Are Absorbing Harness Capabilities
Model companies are now optimizing “model + harness” as a single unit. Many capabilities that originally required harness enforcement have been internalized by models through post-training: tool search, programmatic tool use, compaction/summarization, multi-step tool invocation strategies.
The cycle typically works like this:
• Model teams and community users explore the frontier, discovering which methods actually work
• Training teams take these patterns and incorporate them into post-training
• Models begin internalizing these capabilities; what once required harness enforcement starts becoming native model behavior
• New harness designs emerge to support new model capabilities
• The cycle repeats
Boris Cherny has noted that Claude Code’s harness is being continuously rewritten, with any given line of code having a shelf life of perhaps two months.
Harness as Dataset
Philipp Schmid’s framing bears repeating: the truly valuable data now isn’t just static corpora. It’s the execution trajectories agents generate during real workflows: what information they saw, what tools they used, what decisions they made, which steps went wrong, what feedback made them improve.
In this framing, the harness is no longer mere scaffolding outside the model. It’s the soil from which model capability grows. The quality of that soil will, to a meaningful degree, determine and compound the growth of intelligence.
The current market situation: even though model capability between the two leading labs has largely converged, most people are still using Claude Code. An interesting divergence is emerging: leading model companies are building end-to-end harnesses, while application companies are increasingly training their own models on their own harness and business data.
This competitive dynamic may become one of the most interesting storylines in AI over the next few years.
Where the Startups Are
As harness importance grows, we see emerging startup opportunities across each layer. Here are some representative companies with strong momentum, all of which have recently raised significant rounds from top-tier firms.
Information Layer
One of the biggest bottlenecks in enterprise AI today: agents lack sufficient background information. How to extract the scattered, tacit knowledge trapped inside an enterprise and make it agent-accessible is a significant startup opportunity.
- Edra positions itself as “Context for Agents at Scale.” It automatically ingests tickets, logs, emails, and chat histories, then runs thousands of agents in parallel to reverse-engineer how a company actually operates, compiling reusable agent playbooks. In March 2026, Edra closed a ~$30M Series A led by Sequoia.
Execution Layer
- Temporal provides the underlying infrastructure for durable execution: letting very long, complex, failure-prone tasks run to completion reliably. Clients include OpenAI, Replit, Netflix, Stripe, Datadog, Snapchat, and JPMorgan. In February 2026, Temporal closed a $300M Series D led by a16z at a $5B valuation.
- Oasis Security builds permission management for agentic enterprises. As AI agents increasingly access systems and call data, Oasis helps companies track digital identities, enforce least-privilege access, and maintain auditability. In March 2026, Oasis closed a $120M Series B led by Craft Ventures, Sequoia, and Accel at a $700M valuation.
- Daytona builds sandbox infrastructure for agents. Unlike E2B (a safe execution box), Daytona is more like “giving the agent a long-term-use computer.” In February 2026, Daytona closed a $24M Series A led by FirstMark, with Pace, Upfront, Datadog, and Figma Ventures
Feedback Layer
Evaluation and observability is the layer we’re most optimistic about.
Enterprises need an independent quality control plane; this is an acute pain point today; and once adopted, this layer embeds deeply into AI workflows with high switching costs.
- Braintrust an AI observability and evaluation platform that helps teams see what happens in production (traces), judge quality (human or LLM scoring), and continuously optimize (distilling production issues into test sets). In February 2026, Braintrust closed an $80M Series B led by ICONIQ, with a16z, Greylock, Elad Gil, and Basecase, at an $800M valuation.
From Harness to Coordination
If you look at prompt engineering, context engineering, and harness engineering together, they trace the growth arc of a junior employee. At first, you can only do simple Q&A. Then you get enough business context to do independent research. Then you get tools, permissions, and feedback mechanisms to decompose tasks, use tools, and even lead a few subagents.
The natural question: what comes next?
Following the human career path analogy, the next stage agents need to reach is coordinating countless agents and human nodes to accomplish complex tasks together.
We might call it Coordination Engineering.
OpenAI’s engineering lead and product designer mentioned in a late-January podcast that they’re actively thinking about multi-agent networks:
“Once you enter a multi-agent world, complexity rises fast. How do you manage all of it? How can users always know what each agent is doing, what actions it’s taken, where the workflow stands, and where they need to step in to authorize or correct?”
Stacking these four layers together may constitute the ultimate form of agentic engineering. They’re not a replacement relationship but a containment relationship. As the intelligence waterline rises, the “control plane” keeps shifting upward:
• L1 solves response quality
• L2 solves knowledge boundaries
• L3 solves the execution loop
• L4 solves organizational coordination
And if you extrapolate to the logical extreme? Everything reduces to intention engineering. Human value narrows down to “setting the objective function.” AI handles the rest.
When that day comes, what we call knowledge work may turn out to have been a brief detour in human history.
Decode the Buzzword: Why Harness Engineering Matters Now
Back to All
Harness engineering has become the latest buzzword in the AI engineering lexicon, following prompt engineering and context engineering before it.
The pattern behind this progression is increasingly clear: as foundation model capabilities mature, the real ceiling on agent performance is no longer the model itself. It’s the entire system built around it. For model companies especially, whoever gets the harness right first captures the highest-quality execution trajectories, and whoever keeps capturing those trajectories builds the stronger data flywheel.
DeepMind Staff Engineer Philipp Schmid put it bluntly:
“The Harness is the Dataset. Competitive advantage is now the trajectories your harness captures.”
We recently did a deep dive into this concept, drawing on practices from teams at Anthropic, OpenAI, and Google, as well as conversations with top practitioners in agentic engineering. Here are the key frameworks and takeaways.
Why Harness Engineering Is Having Its Moment
The word “harness” comes from equestrian gear. The analogy is apt: a model is like a powerful but unpredictable horse. Humans use a harness to direct the horse’s behavior and control its path. In the AI context, a harness is the surrounding system that channels model capabilities.
Looking at the timeline, AI engineering methodology has gone through three distinct evolutions:
Prompt engineering (2022–2024) focused on how to express a request. The craft was in shaping single-turn instructions: adding personas, context, goals, examples, all to get the model to reliably produce the desired output.
Context engineering (2025) focused on how to provide the right information. As tasks grew more complex, AI needed access to all relevant background material within a limited context window. The discipline shifted to retrieval, compression, and organization of context.
Harness engineering (2026) focuses on how to build the system. Think of the “system” as everything around the model that makes it actually useful: the runtime environment, tool interfaces, memory systems, evaluation and rollback mechanisms. It’s a complete runtime and control system that lets an agent operate reliably and safely.
If we had to write a definition: Agent = LLM + Harness.
The model decides what to do. The harness decides what the model can see, what tools it can use, and what happens when things go wrong.
The shared logic across all three evolutions: once model capability passes a threshold, the bottleneck migrates outward.
A landmark moment in this migration was the release of Claude Opus 4.5 in November 2025. It signaled that agentic capabilities had reached a tipping point where “using a model well” started to matter more than “making a model better.” The bottleneck had shifted from raw intelligence to the system layer.
Anatomy of a Harness
There’s no absolute consensus on what constitutes a harness, but across the different implementations we’ve seen, we group it into six components:
1. Memory & Context Management :This layer answers: “What information should the agent see right now?” Common approaches include context trimming, compression, on-demand retrieval, and external state stores.
2. Tools & Skills :The action layer. Tools provide callable external capabilities; skills provide reusable task methods.
3. Orchestration & Coordination :The workflow layer that choreographs multi-agent task flows, deciding when to plan, when to execute, and when to hand off, so complex tasks can be decomposed and driven to completion.
4. Infra & Guardrails : The runtime layer providing boundary conditions: sandboxing, permission controls, failure recovery, and safety rails to ensure agents operate securely in real environments.
5. Evaluation & Verification : For many complex tasks, the final quality is determined not by the first-pass generation but by whether a verification loop exists. Many harnesses include built-in testing, checking, and feedback mechanisms so agents can validate their own work and self-correct.
6. Tracing & Observability : The transparency layer that reconstructs agent behavior, providing execution trajectories, logs, monitoring, and cost analysis. A system is only debuggable, optimizable, and manageable when its processes are visible.
From a task-completion perspective, these six components map to a clear pipeline: prepare information, then drive execution, then review results. They can be further grouped into three layers: the information layer, the execution layer, and the feedback layer.
Each component looks simple in isolation. But when these small innovations are woven together, something emergent happens: cross-platform presence, proactive conversation initiation, evolving memory. These are capabilities the model alone doesn’t have.
A Concrete example: OpenClaw’s viral success was largely a victory for harness engineering. It didn’t rely on superior model capability. It created an “aha moment” entirely through harness design. Its core engineering highlights:
• A Gateway layer that unifies WhatsApp, Discord, and other messaging platforms, letting the agent show up like a friend in any channel;
• A built-in Skills library providing a rich set of callable capabilities;
• A memory system that lets it accumulate experience and continuously evolve;
• A Heartbeat mechanism that gives the AI “agency,” letting it wake up and initiate actions on its own schedule;
• Soul.md personality files that inject a vivid persona into otherwise cold code.
Design Principles for the Harness
These principles apply not just to agentic engineers but to anyone using Claude Code or Codex as a knowledge worker.
The biggest bottleneck for agents today remains context length limitations, so harness design is fundamentally organized around this constraint. The information, execution, and feedback layers each have distinct design principles:
1. The Information Layer: Preparing the Right Context
The information layer’s job sounds simple: give the agent the information it needs. In practice, this is where things go wrong most easily, and the failure mode is almost always giving too much rather than too little. Models suffer from context decay: as context grows longer, the model doesn’t linearly “know more.” It becomes more susceptible to noise, and attention to critical information points degrades.
The core design principle: precision over completeness.
Trick 1: Progressive Disclosure
Structure information as a “layered loading” system where the model only touches the layer it needs at each stage, rather than front-loading everything into the AI at once.
OpenAI, for example, tried writing one massive AGENTS.md file with every rule included. It didn’t work. Context is a scarce resource; a massive instruction file crowds out the AI’s capacity to focus on what actually matters.
The current best practice is layered disclosure through the file system. Claude Code organizes core information into three tiers:
• Level 1 CLAUDE.md: Only the most critical, most frequently used meta-rules. It’s an entry point that tells the model the project basics and which principles to follow for different task types.
• Level 2 SKILL.md: On-demand capability packs. Only when a specific task appears does the model load the corresponding skill to learn that task’s methodology.
• Level 3 References, supporting files, scripts: At this layer, the model engages with concrete details rather than abstract principles: documentation, worked examples, architecture info, logs, config files, test commands, or raw script output.
Progressive disclosure is fundamentally about controlling the order of information appearance, keeping the model’s attention concentrated on the most critical 1% of information at any given moment.
Trick 2: Fewer, Better Tools
This one is counterintuitive: as model capability improves, its reliance on external tools should decrease, not increase.
An agent’s power comes not from how many wrenches are in its toolbox, but from whether it has a few perfect “universal wrenches” and how effectively it combines them. Overly complex tool sets are a breeding ground for hallucination. A common failure pattern: as the tool set grows, the agent falls into decision paralysis.
Claude Code has roughly 20 tools today. Even so, the team continually reviews whether each one is truly needed and adds new ones very cautiously.
The Vercel team initially equipped their agent with a comprehensive toolkit covering search, code, files, and APIs. Performance was poor. After trimming to only core tools, both speed and reliability improved significantly.
Trick 3: Find the Context Window Sweet Spot
Multiple independent engineering teams have converged on the same finding: once context utilization exceeds a certain threshold, performance starts declining. Stuffing too much history and background into an agent doesn’t make it stronger; it makes it confused.
The exact sweet spot varies by model, context window size, and task type. In the latest needle-in-a-haystack benchmarks, as input token count scales from 256K toward 1M, virtually every major model shows clear degradation.
The best performers (Opus 4.6 family) still maintain around 70% retrieval accuracy at long contexts, while less robust models (GPT-5.4, Gemini 3.1 Pro) drop to 30%.
Top engineers compress context aggressively, keeping context window utilization below 60%.
Trick 4: Use Subagents for Context Isolation
When the main agent’s context starts getting heavy, farming out subtasks to independent subagents is a viable approach. Each subagent works in a smaller, cleaner context to complete its own task with less noise interference. Once they produce results, the main agent aggregates and orchestrates.
Boris Cherny, Claude Code’s creator, calls this a “context firewall.” For complex tasks, he directs the main agent to “use subagents,” farming out log review, code inspection, and document search. The main thread handles only scheduling and convergence.
2. The Execution Layer: Giving the Agent a Playbook
If the information layer is about “what information the agent sees,” the execution layer is about “how the agent acts.” The most common problem here is task structure design.
Trick 5: Separate Research, Planning, Execution, and Verification
Across top AI labs, a widely adopted practice is deliberately decomposing a single task chain into four steps: research → plan → execute → verify.
Each phase gets its own session with its own context, rather than expecting everything to happen in one shot.
The logic: the agent has limited capacity. Four phases in one context creates unnecessary pollution. Better to spend more compute on cleaner, crisper tasks.
Instead of issuing “Build me an identity verification system,” a better approach:Decide on the approach. (One workflow in the Claude Code team: have one Claude write the plan, then launch a second Claude to review it from a staff engineer’s perspective.)
Boris Cherny’s CLAUDE.md includes an explicit rule:
Enter plan mode for ANY non-trivial task (3+ steps or architectural decisions). If something goes sideways, STOP and re-plan immediately — don’t keep pushing.
In January 2026, he added another refinement: after the user accepts a plan, Claude Code automatically clears context, letting the execution phase start from a clean slate.
Separating research and execution actually ensures the plan gets implemented more accurately.
Trick 6: Human Leverage Belongs in Planning, Not Review
Most people instinctively focus their energy on reviewing outputs rather than designing the upfront plan. In reality, effort should shift forward to the research and planning phases, where leverage is highest. A bad line of code affects one line. A bad line of planning spawns hundreds of bad lines of code.
The further upstream the intervention, the greater the impact per unit of time.
3. The Feedback Layer: The Agent’s Compound Interest Flywheel
The first two layers determine what an agent can do. The feedback layer determines how well the system improves over time. This is the layer most easily overlooked and the one with the strongest compounding effects.
Mitchell Hashimoto wrote:
Anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again.
This represents an engineering discipline: every failure is not an endpoint, but an opportunity to permanently improve the system. The Claude Code team maintains a shared CLAUDE.md with the same principle: whenever Claude makes a mistake, capture that lesson so it doesn’t repeat the same error.
Trick 7: Build Feedback Loops
The highest-ROI investment in harness engineering is building automated feedback and calibration mechanisms for the agent.
Boris Cherny shared that giving Claude effective verification means typically improves final output quality 2–3x. His methods:
• After task completion, prompting another agent to verify results, or enabling stop hooks for self-validation;
• Using the ralph-wiggum plugin to turn the entire flow into “auto-iterate mode,” letting Claude keep doing, keep verifying, keep going until completion criteria are met;
• Having Claude open a browser, test the UI, and iterate until the UX passes.
Karpathy’s autoresearch concept pushes this further. The point isn’t getting AI to produce the best answer in one shot. It’s about getting the AI into a controlled loop: propose an idea → run the experiment → observe results → keep effective strategies, prune dead branches → reflect and propose different improvements → repeat.
The Model-Harness Relationship
The question everyone asks about harness: Will models eat the scaffolding?
Products like Claude Code and Codex are already evidence that model companies are competing not just at the model layer, but on the entire “model + harness” package.
Training Is Deployment
Agent capability ceilings are increasingly determined by environment quality, not just the model itself. In the agentic RL training paradigm, model and harness are not designed separately from the start.
Agentic RL is fundamentally different from standard chatbot RLHF. It involves multi-turn, long-horizon tasks with tool use (a single rollout might invoke tools hundreds of times), a massive action space, extremely sparse reward signals, and heavy dependence on real-environment feedback like test pass rates, code execution results, and linter output.
When Cursor trained Composer 1.5, they used nearly the same production coding environment that serves real users. They spun up hundreds of thousands of sandboxes in parallel, letting the model iterate: what to search, which files to read, how much code to change, when to stop and verify.
Windsurf was explicit when training SWE-1.5:
We believe that the quality of the coding environments in RL tasks is the most important factor for downstream model performance.
Our vision is to co-optimize models and harness: we repeatedly dogfooded the model, noticed issues with the harness, made adjustments to tools and prompts, and then re-trained the model on the updated harness.
Models Are Absorbing Harness Capabilities
Model companies are now optimizing “model + harness” as a single unit. Many capabilities that originally required harness enforcement have been internalized by models through post-training: tool search, programmatic tool use, compaction/summarization, multi-step tool invocation strategies.
The cycle typically works like this:
• Model teams and community users explore the frontier, discovering which methods actually work
• Training teams take these patterns and incorporate them into post-training
• Models begin internalizing these capabilities; what once required harness enforcement starts becoming native model behavior
• New harness designs emerge to support new model capabilities
• The cycle repeats
Boris Cherny has noted that Claude Code’s harness is being continuously rewritten, with any given line of code having a shelf life of perhaps two months.
Harness as Dataset
Philipp Schmid’s framing bears repeating: the truly valuable data now isn’t just static corpora. It’s the execution trajectories agents generate during real workflows: what information they saw, what tools they used, what decisions they made, which steps went wrong, what feedback made them improve.
In this framing, the harness is no longer mere scaffolding outside the model. It’s the soil from which model capability grows. The quality of that soil will, to a meaningful degree, determine and compound the growth of intelligence.
The current market situation: even though model capability between the two leading labs has largely converged, most people are still using Claude Code. An interesting divergence is emerging: leading model companies are building end-to-end harnesses, while application companies are increasingly training their own models on their own harness and business data.
This competitive dynamic may become one of the most interesting storylines in AI over the next few years.
Where the Startups Are
As harness importance grows, we see emerging startup opportunities across each layer. Here are some representative companies with strong momentum, all of which have recently raised significant rounds from top-tier firms.
Information Layer
One of the biggest bottlenecks in enterprise AI today: agents lack sufficient background information. How to extract the scattered, tacit knowledge trapped inside an enterprise and make it agent-accessible is a significant startup opportunity.
- Edra positions itself as “Context for Agents at Scale.” It automatically ingests tickets, logs, emails, and chat histories, then runs thousands of agents in parallel to reverse-engineer how a company actually operates, compiling reusable agent playbooks. In March 2026, Edra closed a ~$30M Series A led by Sequoia.
Execution Layer
- Temporal provides the underlying infrastructure for durable execution: letting very long, complex, failure-prone tasks run to completion reliably. Clients include OpenAI, Replit, Netflix, Stripe, Datadog, Snapchat, and JPMorgan. In February 2026, Temporal closed a $300M Series D led by a16z at a $5B valuation.
- Oasis Security builds permission management for agentic enterprises. As AI agents increasingly access systems and call data, Oasis helps companies track digital identities, enforce least-privilege access, and maintain auditability. In March 2026, Oasis closed a $120M Series B led by Craft Ventures, Sequoia, and Accel at a $700M valuation.
- Daytona builds sandbox infrastructure for agents. Unlike E2B (a safe execution box), Daytona is more like “giving the agent a long-term-use computer.” In February 2026, Daytona closed a $24M Series A led by FirstMark, with Pace, Upfront, Datadog, and Figma Ventures
Feedback Layer
Evaluation and observability is the layer we’re most optimistic about.
Enterprises need an independent quality control plane; this is an acute pain point today; and once adopted, this layer embeds deeply into AI workflows with high switching costs.
- Braintrust an AI observability and evaluation platform that helps teams see what happens in production (traces), judge quality (human or LLM scoring), and continuously optimize (distilling production issues into test sets). In February 2026, Braintrust closed an $80M Series B led by ICONIQ, with a16z, Greylock, Elad Gil, and Basecase, at an $800M valuation.
From Harness to Coordination
If you look at prompt engineering, context engineering, and harness engineering together, they trace the growth arc of a junior employee. At first, you can only do simple Q&A. Then you get enough business context to do independent research. Then you get tools, permissions, and feedback mechanisms to decompose tasks, use tools, and even lead a few subagents.
The natural question: what comes next?
Following the human career path analogy, the next stage agents need to reach is coordinating countless agents and human nodes to accomplish complex tasks together.
We might call it Coordination Engineering.
OpenAI’s engineering lead and product designer mentioned in a late-January podcast that they’re actively thinking about multi-agent networks:
“Once you enter a multi-agent world, complexity rises fast. How do you manage all of it? How can users always know what each agent is doing, what actions it’s taken, where the workflow stands, and where they need to step in to authorize or correct?”
Stacking these four layers together may constitute the ultimate form of agentic engineering. They’re not a replacement relationship but a containment relationship. As the intelligence waterline rises, the “control plane” keeps shifting upward:
• L1 solves response quality
• L2 solves knowledge boundaries
• L3 solves the execution loop
• L4 solves organizational coordination
And if you extrapolate to the logical extreme? Everything reduces to intention engineering. Human value narrows down to “setting the objective function.” AI handles the rest.
When that day comes, what we call knowledge work may turn out to have been a brief detour in human history.