
Generalist and its 270,000-Hour Advantage
back to All
Robotics is a sector we have followed closely over the long term, and Generalist is one of the very few companies in the robotics field that demonstrates durable competitive potential. Its core strengths are concentrated in data scale, team capabilities, and a clearly defined scaling path.
Looking beyond any single company, we believe that, although robot data remains extremely scarce at present, if model performance can be continuously improved through a combination of human video and real-world robot data, the competitive focus may shift from data scale to data recipe.
The team that first successfully implements and engineers the optimal data recipe may not only achieve a performance lead but also set a demonstrative precedent for the entire industry.
01 Why Generalist?
Generalist has accumulated a large amount of real-world robot data, giving it a 6–12 month lead over other teams.
Currently, methods for collecting robot data can be roughly divided into three categories:
- Real-world data collection, which requires interaction with the physical environment.
1)Teleoperation: Robots are deployed at the front end while humans control them from the back end to complete tasks and collect data. This method achieves the highest data accuracy but is costly and constrained by the number of robots and the available environments.
2)Embodiment-free data collection (UMI): No physical robot is required; humans directly manipulate a gripper or wear an exoskeleton to collect data. Due to issues such as the lack of full-body information, this approach places higher demands on algorithms, particularly relying on high-precision localization and mapping. However, it is more efficient, lower in cost, and better suited for use in complex environments such as outdoors.
- Pure video data collection: Learning relies solely on video data; while the collection cost is low, the data efficiency is relatively limited.
- Synthetic data: Data is generated by constructing simulated environments and automatically producing data based on predefined rules or programs, offering advantages in controllability and scalable generation.
The prevailing view is that training usable robot models still requires real-world data. Real data is not inherently unscalable, but it cannot multiply as easily as in simulation.
A researcher once roughly converted the number of LLM tokens into data duration to draw an analogy between LLMs and the current stage of robotics development:
Assuming a human speech rate of 238 words per minute, with one word roughly equivalent to 1.33 tokens, one hour of human language data corresponds to approximately 19,000 tokens. By this measure, GPT-1 used about 5 billion tokens, equivalent to 270,000 hours of human language data, while the training scale of GPT-3 rises to approximately 15.8 million hours.
Looking further, according to SemiAnalysis, the base training data volume of GPT-4 is approximately 13 trillion tokens, equivalent to about 684 million hours.
Currently, the mainstream scale of real-world robot training data in the industry is around 10,000 hours, meaning that the vast majority of players are still in the "pre-GPT era," and data is extremely scarce within the industry. In this context, Generalist, which claims to have 270,000 hours of training data, may be the only robotics company in the world to have just reached the GPT-1 threshold in terms of data scale.
Moreover, replicating this scale of data is not merely a matter of money but also of time. Another researcher once stated that manufacturing dedicated data collection hardware alone takes 4–6 months, and to replicate 270,000 hours of data would require at least 1,000 people continuously collecting for over half a year to nearly a full year. Consequently, Generalist has a 6–12 month lead over other teams.
The team has a very high talent density and solid technical foundation.
The team possesses a very strong technical capability. The three co-founders combine top-tier academic backgrounds from MIT and Princeton with industry R&D experience at Google DeepMind and Boston Dynamics, and are major contributors to milestone embodied intelligence projects such as PaLM-E and RT-2. They have proven technical experience in the co-design of algorithms and hardware. Moreover, the core members share a long-standing history of academic collaboration and prior entrepreneurial experience together, providing a deep foundation of trust that reduces internal friction and management costs during the early stages of the startup.
In addition, Generalist regards scaling as part of its company DNA. Formerly Head of Engineering at OpenAI, Engineering Lead Evan Morikawa led the engineering teams for ChatGPT, GPT-4, DALL·E, and API products, possessing extensive experience taking projects from 0 to 1 and then to large-scale deployment.
Overall, compared with Physical Intelligence, both Generalist and PI possess top-tier industry capabilities in core algorithmic insights. In terms of team-building strategy, PI leans toward an all-star lineup with more comprehensive member composition, whereas Generalist's team is more streamlined.
A series of demos showcase the models' exceptional dexterity and the team's clear research approach.
Generalist prioritizes dexterity as its top focus in robotics. This commitment is reflected in a series of key milestones: high-frequency dynamic manipulation demonstrated in June 2025, sub-millimeter precision achieved in the LEGO assembly task this September, and GEN-0's advanced capabilities in tool use, deformable object handling, and high-precision assembly. Collectively, these achievements validate the effectiveness of Generalist's methodology for addressing challenges in physical interaction.
Moreover, Generalist's models possess low-level motion generation capabilities: under end-to-end control, they can still produce smooth and precise operational strategies. This ability to enable robots to exhibit dexterity akin to biological instincts in complex environments is currently extremely rare in the market and very difficult to replicate.
Potential Risks
Uncertainty in extrapolation: Does the scaling law hold in the robotics domain?
In November last year, when Generalist released the GEN-0 model it claimed to have validated a scaling law analogous to that of language models for the first time in the robotics domain, whereby downstream task performance exhibits a predictable power-law improvement as pre-training data and compute increase.
If the scaling law does not hold, it would imply a fundamental limitation of deep learning in the physical world, potentially requiring a reevaluation of the valuation logic for the entire embodied intelligence sector. However, the prevailing view leans toward the validity of the scaling law, which implies that the upper limit of intelligence will, to some extent, depend on the ability to collect large-scale data. The forthcoming divergence in development will concern the type of data required.
If foundational models can improve performance through a mix of human video data and real-world robot data, then the competitive factor may no longer be data scale alone, but rather who can first implement the optimal data recipe. The team that first validates and engineers an effective mixed data recipe may not only achieve a performance lead in modeling but also materially advance the evolution of robot training paradigms, setting a demonstrative example for the entire industry.
At present, even with the introduction of human video data, models may still require an equal or even greater amount of real-world robot data to achieve optimal performance. Some researchers even suggest that hardware could account for 70–80% of the value in the robotics field. Therefore, if future robot training continues to rely heavily on large amounts of real-world data, although Generalist has also deployed some hardware for data collection, companies with inherent hardware capabilities such as Tesla and Figure may hold a comparative advantage.
The "GPT-3 moment" for robotics still requires massive amounts of data.
Although Generalist has reached the GPT-1 level (270,000 hours), achieving the equivalent of GPT-3 (15.8 million hours), based on Generalist's current collection rate of 10,000 hours per week, would linearly extrapolate to approximately 30 years. If reaching GPT-3 requires solely real-world data collection, this path may be economically unfeasible for a startup.
This in turn increases the urgency of training models using synthetic data or human video data. If it is later found that models can be sufficiently trained with synthetic or human video data alone, the physical data collection moat established by Generalist could be circumvented.
Lack of commercial use cases.
The robotics industry as a whole currently lacks clear paths to commercialization. Under the premise of self-built data collection hardware and collaboration with Scale AI for annotation, Generalist faces higher cost inputs. At present, the demos publicly showcased by the company remain primarily at the level of stacking LEGO or folding clothes. In contrast, Sunday, which focuses on home environments, is closer to practical deployment.
02 Does Scaling Laws Exist in Robotics?
Early models released by Google, such as PaLM-E and RT-2, produced findings similar to "as model parameters increase, performance and generalization on embodied tasks improve," but Google did not publicly claim to have validated a scaling law in the robotics domain.
In 2024, researchers from MIT and the Technical University of Munich analyzed 327 papers, including models released by Google, and concluded that foundational robot models do exhibit scaling laws, with new robotic capabilities continuously emerging as model scale increases.

In November last year, Generalist claimed to have validated a scaling law analogous to that of language models for the first time in the robotics domain, whereby downstream task performance exhibits a predictable power-law improvement as pre-training data and compute increase. International social media largely regarded this as a significant breakthrough. Ted Xiao, a former Google DeepMind scientist who participated in projects such as Gemini Robotic, RT-2, RT-1, and SayCan, described the result on Twitter as very promising.
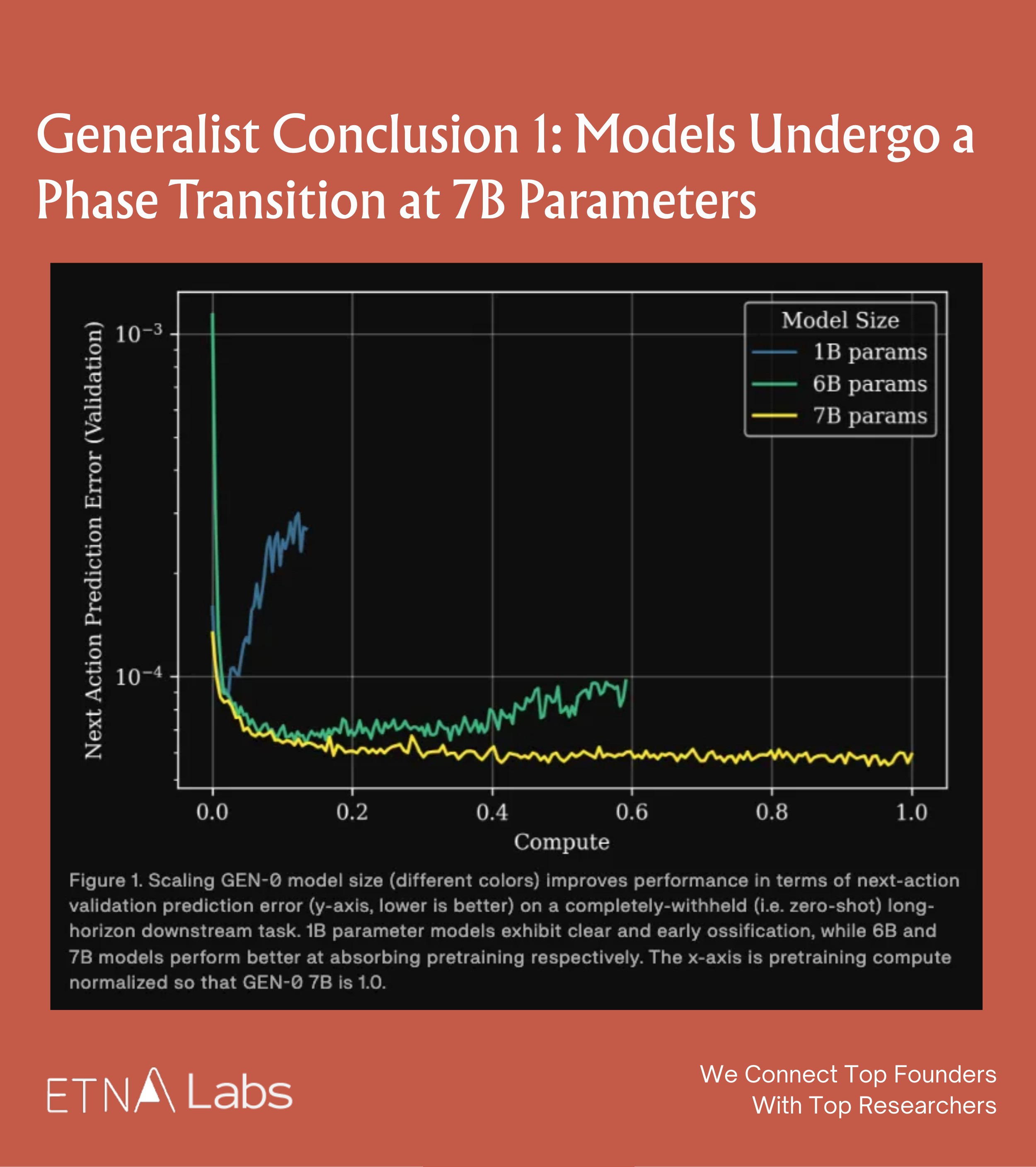
Generalist Conclusion 1: Models Phase Transition at 7B
When the Generalist team studied the effect of model parameter size on learning ability, they observed a distinct phase transition phenomenon:
- When the model has a small number of parameters (e.g., at the 1B level), even with massive data input, the training loss stagnates after reaching a certain point. In other words, the model becomes "rigid" and cannot absorb additional information.
- The 6B model begins to benefit from pre-training and demonstrates strong multitask capabilities. When the model is scaled beyond 7B parameters, a phase transition occurs: the large model can continuously absorb data and the training loss keeps decreasing. This indicates that only by crossing this parameter threshold can the model truly acquire general capabilities through pre-training.
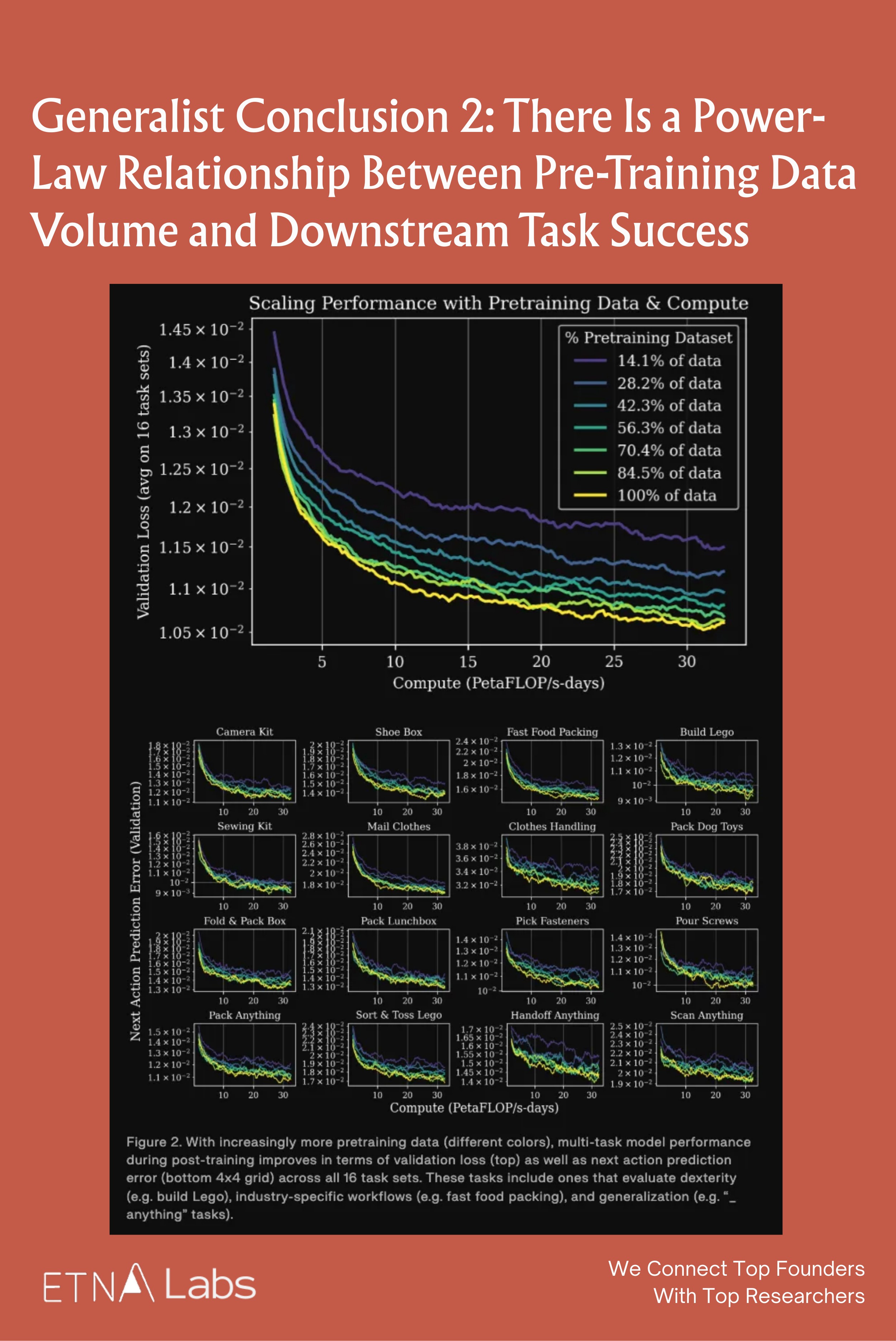
Generalist Conclusion 2: Power-Law Between Data Volume and Task Success
Furthermore, at sufficient model scale, there exists a significant power-law relationship between the volume of pre-training data and final performance on downstream tasks, which has been validated both at the level of model metrics and real-world robot experiments.
In terms of model metrics, the team selected model checkpoints trained with varying amounts of pre-training data and performed multitask supervised fine-tuning across 16 different task sets. The results show that the more pre-training data used, the lower the validation loss and next-step action prediction error of the downstream models across all tasks.
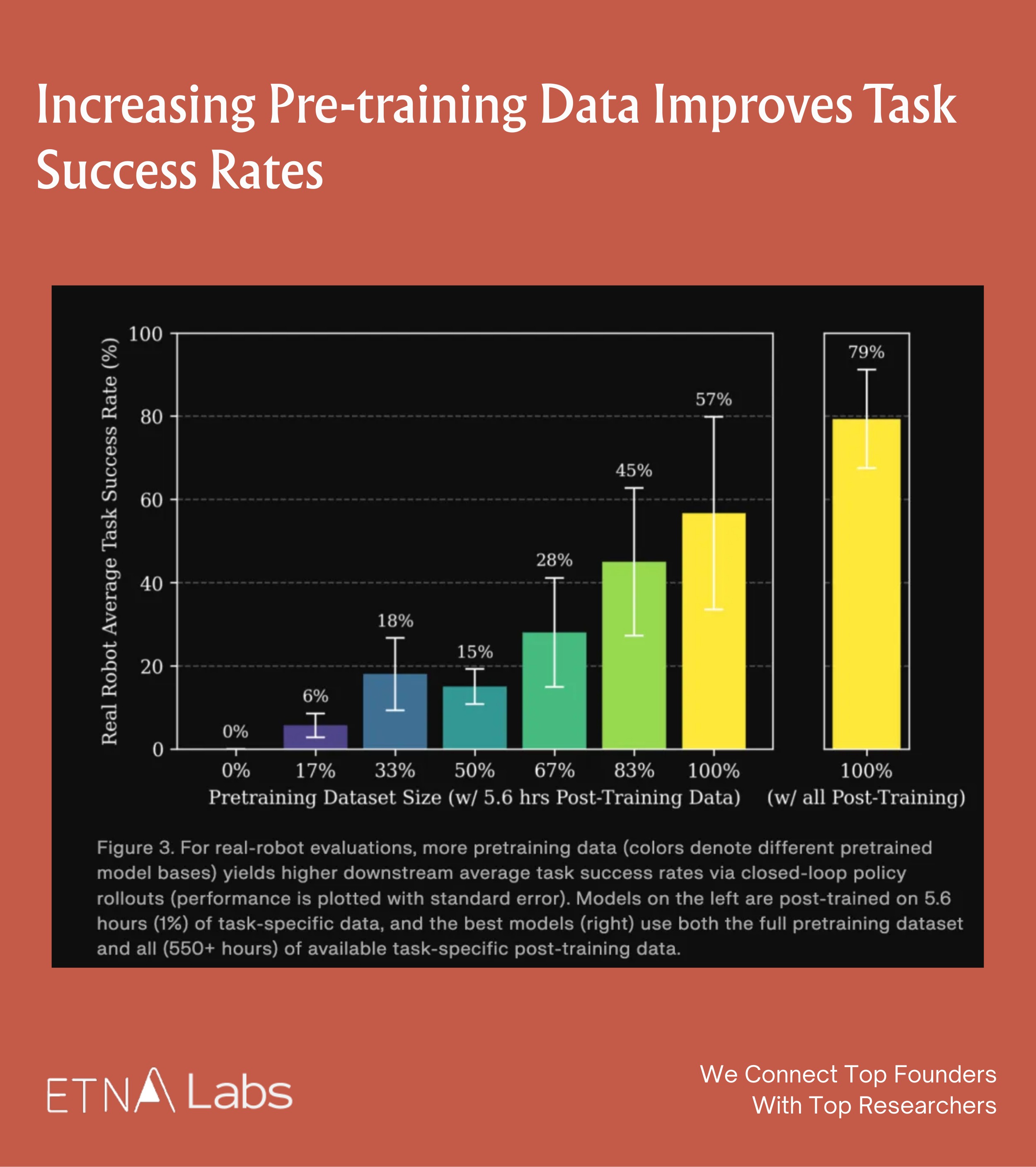
In practice, this trend was confirmed on physical robots through blind A/B test. The team ensured that pre-training and post-training data did not overlap in the experiments. The results show that increasing pre-training data improves task success rates: even with only 5.6 hours of downstream data, the gains were substantial. When the full pre-training dataset was combined with sufficient downstream data (550+ hours), task success rates reached their maximum, with peak performance in some scenarios reaching 99%.
Finally, this performance trend was formalized into a predictable mathematical model. Based on the established power-law relationship, the team is able to answer questions such as "how much pre-training data is required to achieve a specific error" or "how much downstream fine-tuning data can be offset by additional pre-training data."
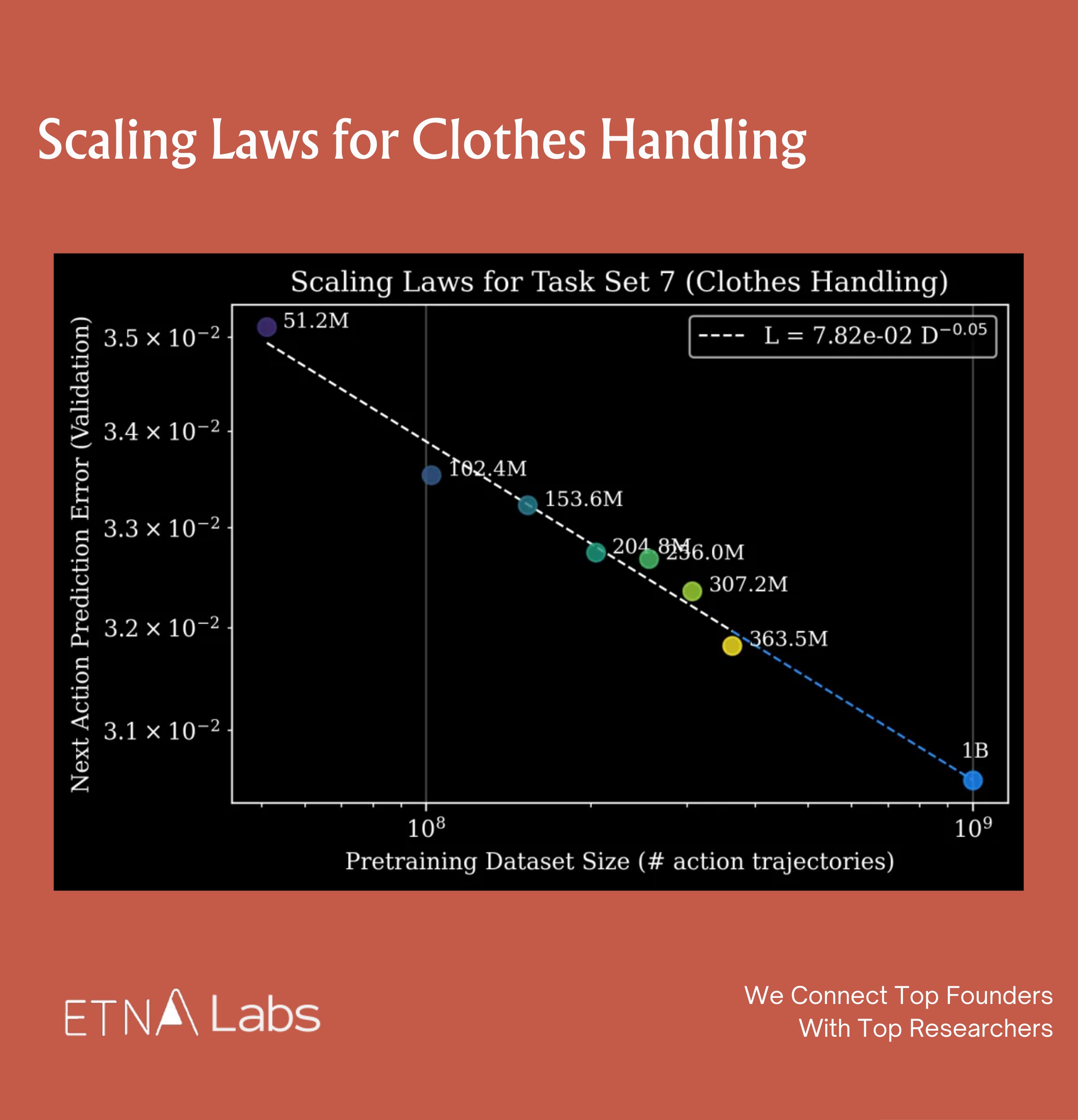
Generalist Conclusion 3: Data Quality & Diversity Trump Volume
The team also compared the impact of different data sources on model performance and found that data quality and diversity matter more than the quantity of data itself: pre-training data from different sources (e.g., different data foundries) can produce models with distinct characteristics depending on the combination used.
For example, some data configurations produced models with both low prediction error and low reverse KL divergence, making them more suitable for supervised fine-tuning. Other configurations, while exhibiting higher prediction error, showed low reverse KL divergence, indicating that the model's output distribution had higher multimodality, which is more advantageous for reinforcement learning.
Research from Physical Intelligence
In the past, due to the significant differences in morphology and movement between human hands and robotic arms, robots found it difficult to learn directly from human video, so typically requiring complex feature alignment processing.
In December 2025, Physical Intelligence demonstrated in Emergence of Human to Robot Transfer in VLAs that, by simply scaling up the pre-training of foundational robot models, the models exhibit the ability to learn from human video:
- In tasks such as sorting eggs by color or organizing a dressing table, the introduction of relevant human data improved the robot's performance by approximately twofold.
- Without large-scale pre-training, the model treats human and robot data as entirely distinct features. As the diversity of robot data in pre-training increases, the model's internal representations of human and robot features begin to align automatically, enabling it to "understand" demonstrations in human video.
To achieve this, the research team employed a co-finetuning strategy using both human and robot data. It should be noted, however, that
- Fine-tuning is not simply a matter of mixing all the data together; rather, human data is combined with the most relevant real-world robot data. For example, in egg-sorting tasks, the robot data provides the basic motor skills of "placing eggs into a carton," while the human data supplements high-level logic demonstrations such as "sorting eggs by color."

- Believed that this proportion both preserves the model's original robotic manipulation capabilities and effectively incorporates human demonstrations, PI used a 1:1 data mixing ratio in the paper. However, the paper did not provide comparative results for other ratios, such as 3:7.

Google's Experience: PaLM-E, RT-2
Generalist's CEO Pete Florence previously led or participated in several major robotics projects at Google, including PaLM-E and RT-2.

PaLM-E validated that as model parameter scale increases, overall performance on embodied tasks continues to improve without exhibiting the catastrophic forgetting commonly seen in traditional multitask learning. At the same time, PaLM-E demonstrated significant positive transfer: training on language and vision tasks (such as Web VQA) not only does not interfere with robot control but actually enhances robotic execution capabilities, reflecting the characteristic of "the more you read, the smarter you work." At sufficiently large model scales, multimodal chain-of-thought capabilities also emerge, enabling the model to perform more complex reasoning across vision, language, and action.
RT-2 further demonstrated improvements in generalization capabilities. Compared with earlier models such as RT-1, which did not transfer semantic reasoning abilities from large-scale network knowledge, RT-2 leverages a VLA architecture with hundreds of billions of parameters, along with joint fine-tuning on multimodal and robot data to exhibit generalization even for previously unseen task instructions.
03 Generalist Puts Model Dexterity First
With the goal of building general-purpose robotic models, Generalist was founded in 2024 and treats scaling AI and robotics as the company's DNA. In the field of robotics, the company places its greatest emphasis on dexterity, which it believes requires breakthroughs across the data, model, and hardware layers. In March 2025, Generalist completed a seed funding round led by Nvidia (NVentures) and Boldstart Ventures.

GEN-0
In November 2025, Generalist released its foundation model GEN-0 and demonstrated the model's integrated capabilities through a long-sequence task:Place the
- cleaning cloth into the box;
- Fold the paper pallet;
- Remove the camera from the plastic bag and take off the protective cover;
- Place the camera precisely into the tray;
- Close the box lid (requiring alignment of small tabs);
- Dispose of the waste (discard the plastic bag).
In completing this task, the model was not provided with step-by-step instructions but instead executed all steps within a single neural network flow, demonstrating its capabilities in deformable object manipulation and high-precision assembly. In addition, GEN-0 also demonstrated cross-embodiment capabilities: the model has been successfully deployed on 6-DoF robotic arms, 7-DoF robotic arms, and semi-humanoid robots with 16+ DoF.
Across social media platforms such as X and Reddit, the public has broadly expressed admiration for GEN-0's dexterity and the level of task precision it can achieve. Stanford robotics professor Shuran Song described the robot's ability to perfectly insert the box lid as satisfying on X.

Demo Before GEN-0
In June of last year, the company published its first blog post, in which the robot was fully autonomous in all demos and controlled in real time by a deep neural network. The network directly maps pixels and other sensor data to 100 Hz action commands, and the blog presented four specific tasks:
- Sorting fasteners: demonstrating the ability to rapidly grasp, reorient, and sort small, flat objects from clutter.
- Folding a box and packaging a bike lock: demonstrating long-sequence capabilities in handling articulated objects (the box) and deformable objects (the chain lock), as well as the millimeter-level precision and force control required in the process.
- Recycling screws: demonstrating tool use and complex bimanual coordination (such as scraping screws off a magnetic bit and bending a paper tray into a funnel).
- Disassembling, sorting, and tossing LEGO bricks: demonstrating strong bimanual coordination (disassembly), regrasping, generalization (recognizing different brick structures and bin position), and high-speed actions (tossing).
Building on the LEGO task demonstrated in June, the company introduced a new internal task for evaluating robotic capabilities: imitation-based construction with LEGO bricks in September. The company cited third-party perspectives that categorize imitation-based LEGO construction as the highest level (Level 4) of general-purpose robotics, namely the ability to perform force-dependent, fine-grained tasks with extremely high precision and to respond subtly to the physical forces of the environment.
Specifically, a human first assembles a small LEGO structure. After which, the robot is able to replicate an identical structure from scratch by observing it. For this task, the company again adopted an end-to-end approach: the model directly ingests visual pixel inputs and generates action commands at 100 Hz, with no task-specific engineering or custom instruction code required. The robot operates entirely by understanding its visual input and executing corresponding actions.
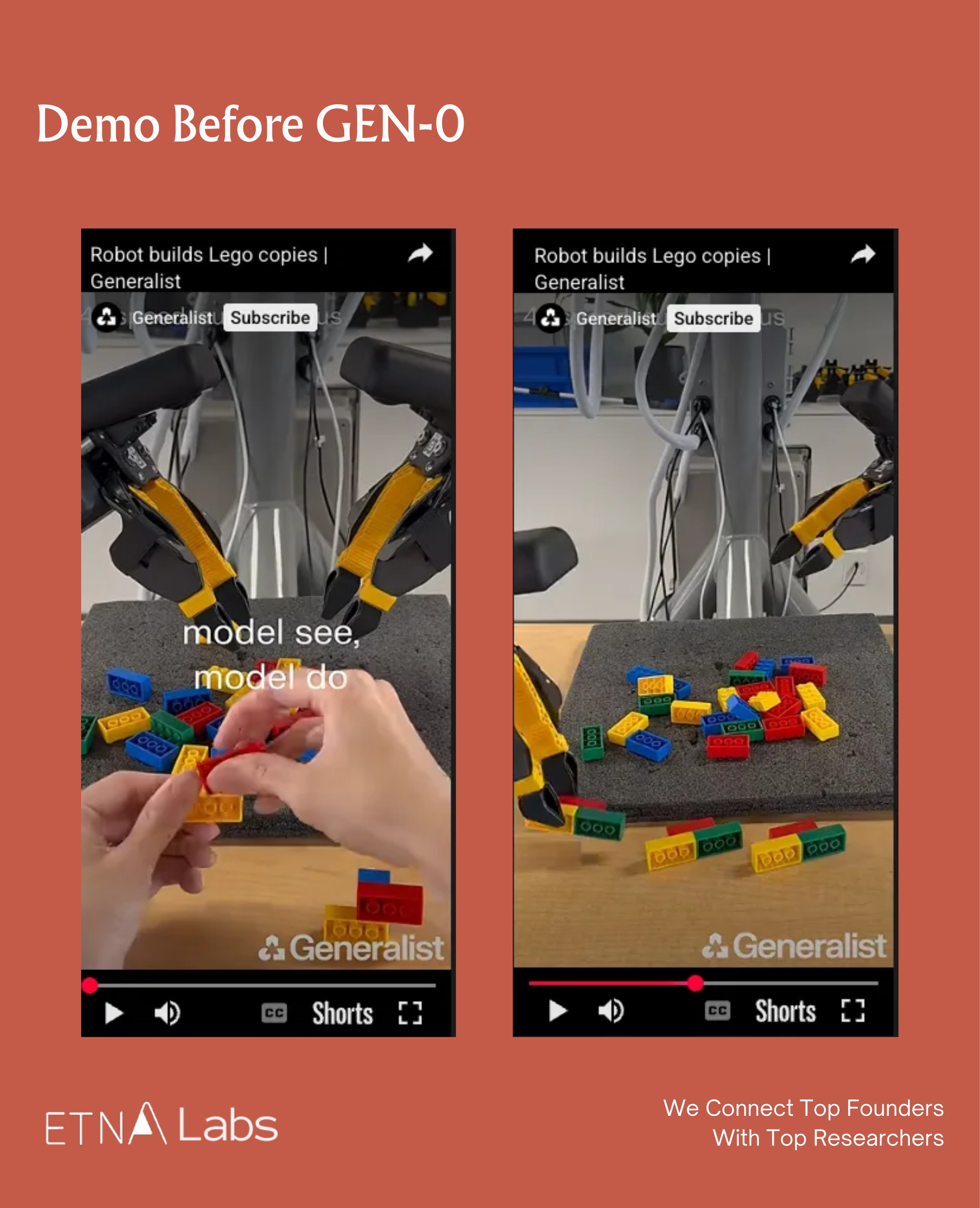
The highlights of these demos are as follows:
- Extremely high dexterity: Assembling LEGO requires sub-millimeter precision, aligning studs correctly and applying the right pressure—far more difficult than disassembly or tossing, as shown in the June demos.
- Visual understanding and imitation: The robot can infer construction goals by observing a human-built structure, rather than merely executing predefined actions.
- Sequential reasoning: It plans each step—selecting the correct block, adjusting orientation, positioning, and assembling—to achieve the final configuration.
- Generalization: Although demos are limited to three-layer structures using 2×4 bricks in four colors, the potential combinations number roughly 99,840. This demonstrates the robot handles diverse structures beyond rote memorization.
04 Technical Barriers of the Generalist: Data, Hardware, and Models
Data Collection
In terms of data volume, GEN-0 used over 270,000 hours of real-world robotic operation data for pre-training, sourced from various activities across thousands of homes, warehouses, and workplaces worldwide. The data feedback loop is also accelerating, currently adding at a rate of 10,000 hours per week.

- How does Generalist collect data?
Generalist uses UMI for data collection, achieving parallel and diverse data gathering by deploying thousands of data collection devices and robots worldwide.
A comment on Reddit mentioned that the company collects data using gloves, with the fingers of the gloves resembling the robotic grippers, allowing humans to wear them while performing everyday chores and tasks. Based on a data collection video released by the company, it is inferred that the wearer has a camera mounted on their head, with each glove also containing a camera.

Generalist also collaborates with multiple data foundries to collect diverse data across different environments. Through continuous A/B testing, they are able to assess the data quality from each partner and adjust the data procurement ratio accordingly.

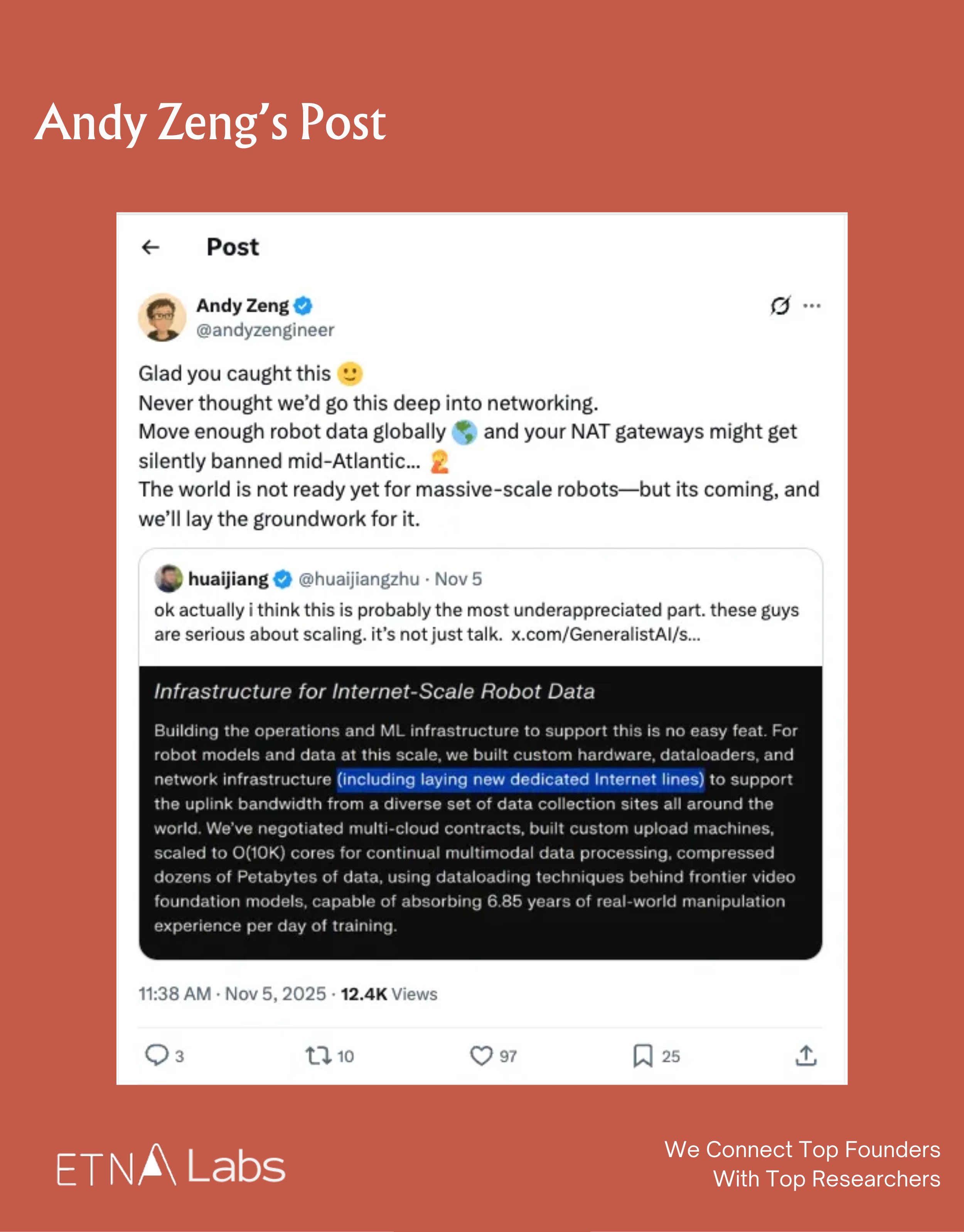
- How does Generalist process data?
The company has built dedicated hardware and processing pipelines, and even laid dedicated Internet lines, to support high-bandwidth data uploads from various sites to the cloud. This infrastructure allows them to process data equivalent to 6.85 years of human operational experience per day.
- How high are the costs of data collection?
The information report indicates that Generalist's data supplier is Scale AI. The Engineering Lead of 1X stated that Scale AI previously hired college students to label data in the CS field, charging $50 per hour, and then sold it for $200 per hour. Based on this, the data collection cost for Generalist can be roughly estimated.
A comment on X suggests that even in China, collecting the data to train GEN-0 would cost between 2 to 3 million.

Hardware
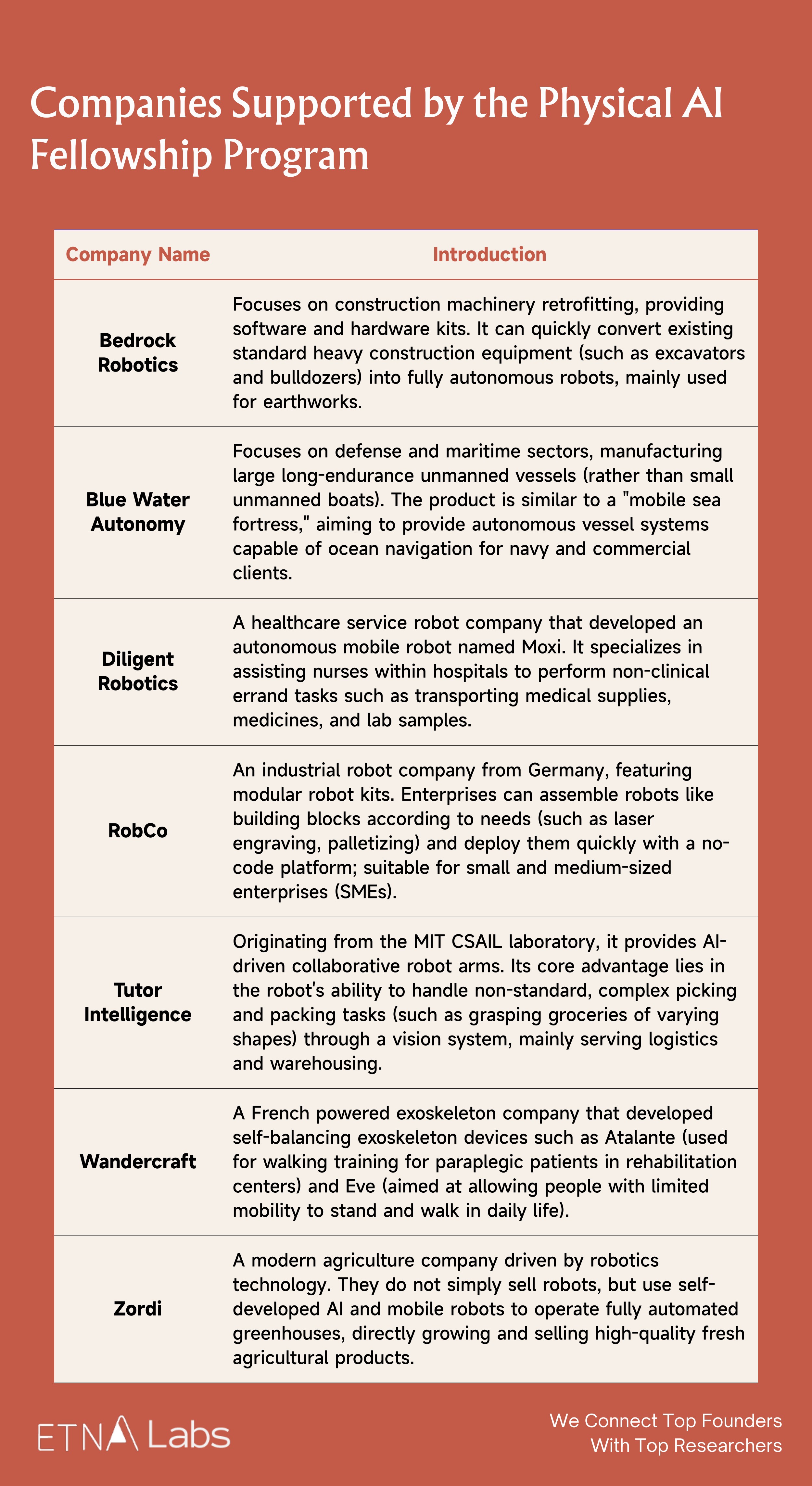
In addition to the aforementioned data collection hardware, in September of last year, Generalist AI became one of the first eight startups selected for the Physical AI Fellowship program (Fall 2025).
The program launched by MassRobotics in collaboration with AWS and NVIDIA Inception, aims to accelerate the development of startups in the field of Physical AI by providing technical resources. Selected companies primarily receive the following support:
- Technical support from scientists and engineers at the AWS Generative AI Innovation Center.
- $200,000 AWS cloud service credit, along with support from NVIDIA's hardware and software technology stack, and access to software and hardware at discounted prices through the NVIDIA Inception startup program.
- Access to MassRobotics' global robotics partner network.

In addition to Generalist, the first cohort also includes Bedrock Robotics, Blue Water Autonomy, Diligent Robotics, RobCo, Tutor Intelligence, Wandercraft, and Zordi.
Model Architecture
Traditional robotic architectures typically divide the robot model system into system 2 and system 1. Employing a mechanism called Harmonic Reasoning, GEN-0 abandons this separation, which represents an architectural innovation that differentiates GEN-0 from conventional robotic models.
Specifically, this architecture integrates perception tokens and action tokens within the same Transformer stream, enabling the model to "think while acting." It does not need to pause for planning, but can generate continuous, smooth, and intelligent actions at a very high frequency (100 Hz+).
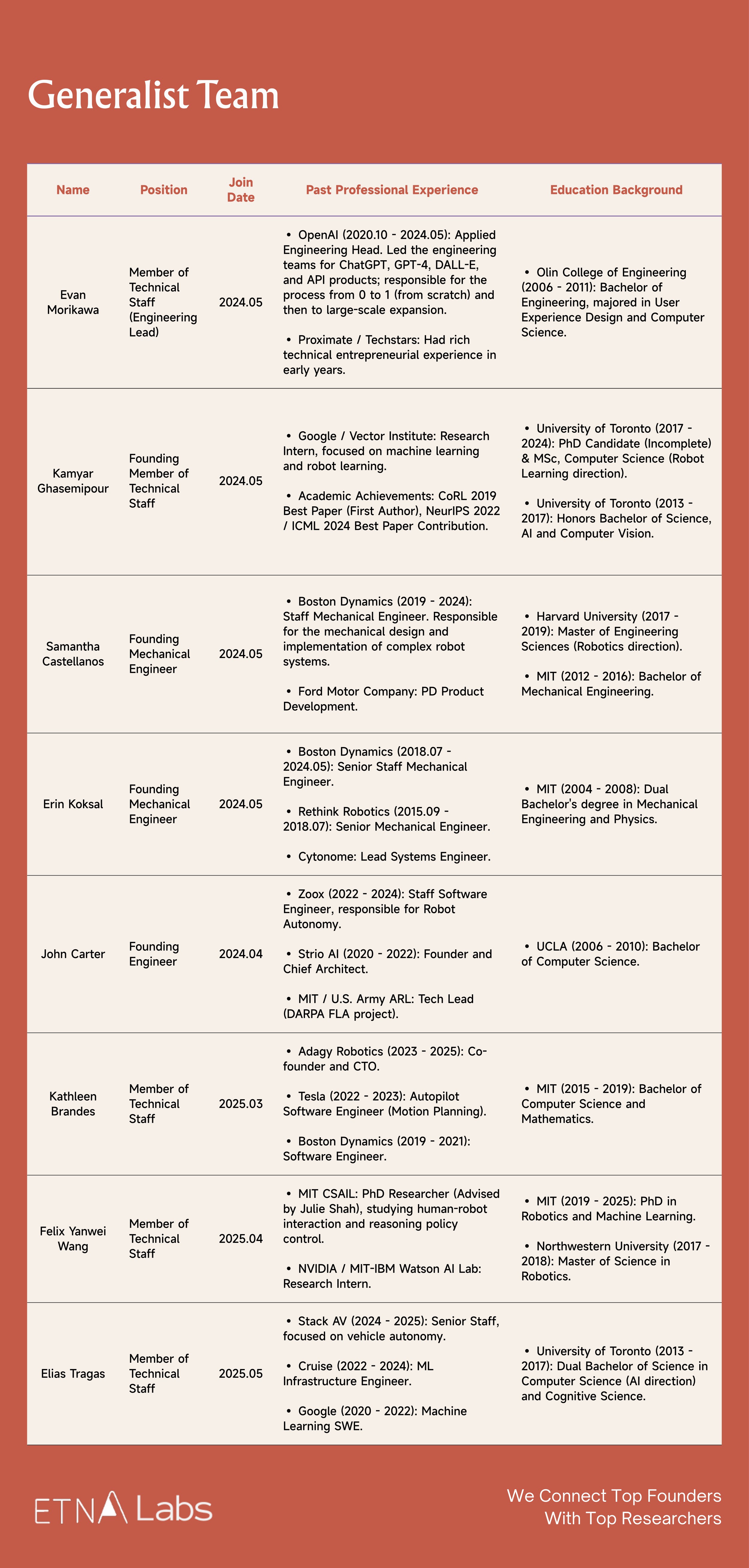
05 Generalist Team
Generalist team members come from institutions such as OpenAI, Boston Dynamics, and Google DeepMind. Prior to joining Generalist, some members participated in the research and release of models like PaLM-E and RT-2, were responsible for scaling ChatGPT and GPT-4 to hundreds of millions of users, or were involved in the development of key autonomous driving technologies and robotic systems such as Atlas, Spot, and Stretch.
- Pete Florence (CEO & Co-founder)
Florence previously served as a Senior Research Scientist at Google DeepMind and earned his PhD from MIT in 2019, during which he focused on vision-guided robotic manipulation and produced representative work such as Dense Object Nets, emphasizing end-to-end learning from raw perception to action. After graduation, he joined Google, where he led or participated in several major robotics projects including PaLM-E and RT-2. In 2024, Florence left Google to found Generalist. Notably, in March of last year, DeepMind cited Florence's co-authored research four times in the Gemini Robotics paper.
- Andrew Barry (CTO & Co-founder)
Andrew Barry previously served at Boston Dynamics, where he was involved in the development of key robotic systems. Andrew and Pete were both students of Russ Tedrake, and their academic collaboration began with research on a lightweight stereoscopic vision-based obstacle avoidance algorithm for drones. Previously, they co-founded the educational workshop Stage One Education, which teaches basic engineering concepts to children in an accessible manner, having reached over ten thousand students.
- Andy Zeng (Chief Scientist & Co-founder)
Andy Zeng previously served as a Research Scientist at Google DeepMind, with a primary focus on robotic grasping and object understanding. He earned his PhD from Princeton University in 2019 and received multiple awards for his research in robotic grasping and visual perception.
His representative work, TossingBot (a system capable of autonomously learning to throw different objects, with Shuran Song as second author) was nominated for the RSS 2019 Best Systems Paper Award. Andy interned at Google as early as 2018 and later joined the company as a core member of the robotics team, working closely with Pete Florence, co-authoring over seventeen papers, and gaining wide attention for research such as "Code as Policies," which enables robots to generate their own code.
- Other members
06 Competitive Landscape
There are numerous startups in the robotics field. If scene complexity is plotted on the vertical axis and delivery format on the horizontal axis, a rough quadrant map of the robotics industry can be drawn. In the past, market attention was primarily focused on the lower half, covering relatively structured environments such as factories and logistics, where task determinacy was higher. With the development of LLMs, market focus has shifted toward the upper half.

- Quadrant I (top right):Consumer-grade general-purpose robots.Sunday — emphasizes practicality, collects data using low-cost gloves, aims for deployment in home environments
- Quadrant II (top left):General-purpose embodied brains.Physical Intelligence — focuses on developing robotic brains, does not produce hardware itself, but engages in hardware partnerships
- Quadrant III (bottom left):Robotic brains for vertical domains.Covariant — started in the logistics sector; in August last year, Amazon reached an agreement, "acquiring" the three co-founders and the core research team
- Quadrant IV (bottom right):Vertical domains via extreme hardware-software integration.Amazon Robotics — focuses on highly customized solutions to maximize efficiency within its own warehouses
Strengths and Weaknesses of Generalist
As a newly established general-purpose robotic brain company, Generalist is positioned in Quadrant II. Overall, Generalist's greatest moat remains its large volume of end-to-end real-world robot data and extremely strong technical team. However, it also faces significant competitive pressure: Physical Intelligence has a more complete team structure and has recently completed substantial funding; Google possesses massive TPU compute resources and financial backing, as well as the ability to leverage the Gemini model; Sunday, meanwhile, achieves faster deployment in home environments.
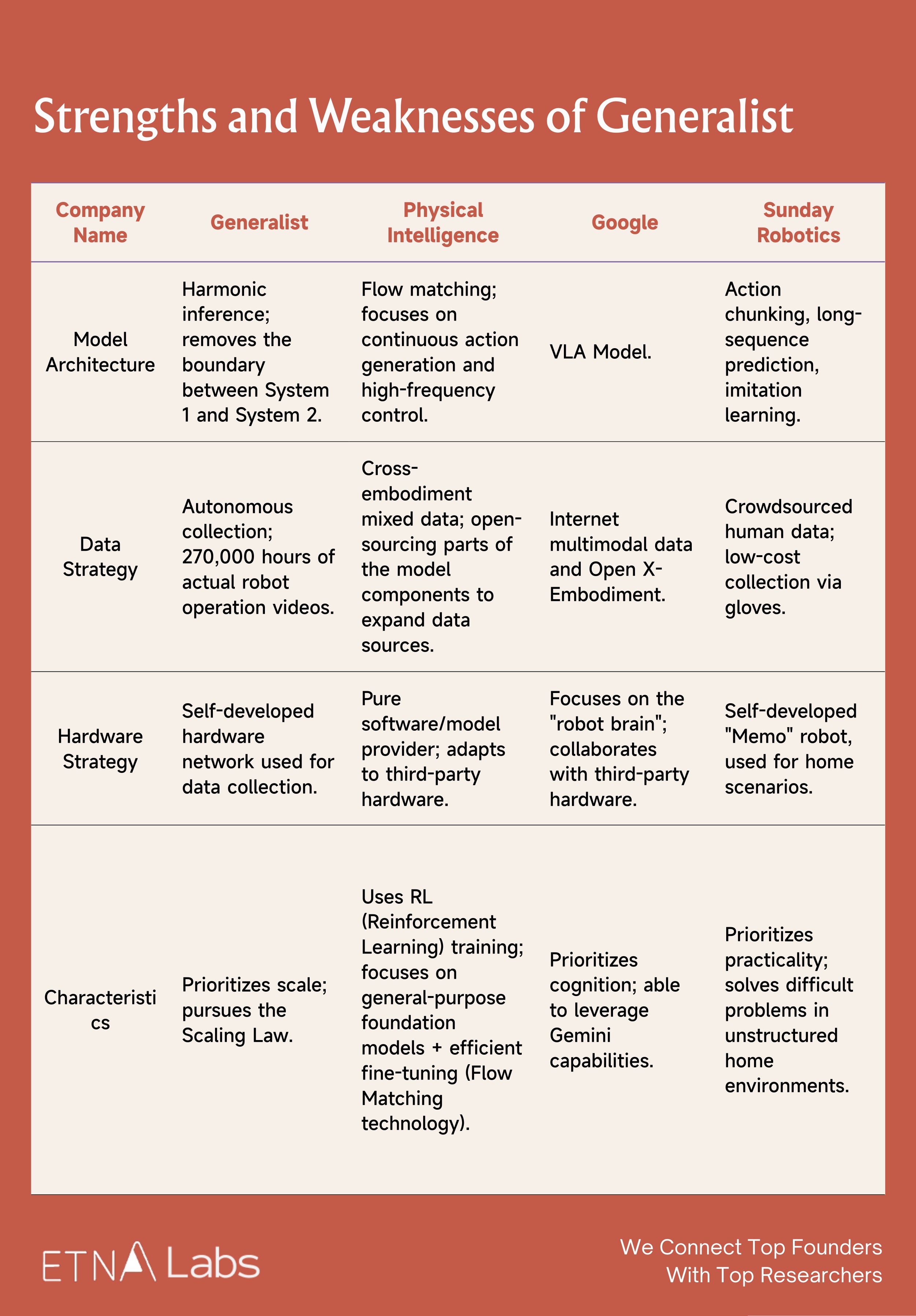
- Generalist vs Physical Intelligence
Technically, PI's Flow Matching technology can directly output continuous and smooth motor signals, addressing the stiffness in actions caused by discrete tokens in traditional motion generation models (such as Google RT-2). Additionally, PI's Recap algorithm endows the model with self-improvement capabilities, allowing it to increase task throughput and reduce failure rates through expert corrections and autonomous trial-and-error. Generalist currently lacks such a post-deployment "improvement through use" mechanism.
In terms of ecosystem and team building, PI actively cultivates an ecosystem and engages in open collaboration with robotics hardware companies, whereas Generalist's demos are currently limited to desktop operations and lack validation in real production lines. PI's team includes multiple academic luminaries such as Chelsea Finn and Sergey Levine, forming an all-star lineup with a more comprehensive team structure; by comparison, Generalist's team is more streamlined.
Additionally, in November 2025, PI announced the completion of $600 million in funding with a valuation of $5.6 billion, placing it ahead in terms of financing progress.
- Generalist vs Google
In terms of ecosystem, Google has adopted an "Android for Robots"–style open strategy, connecting global laboratories and hardware manufacturers through the Open X-Embodiment Alliance. Generalist, however, lacks Google's ecosystem control to rapidly deploy models across different hardware platforms, and therefore may need to establish sufficiently high barriers in data quality and dexterous manipulation.
Moreover, this is a prolonged battle with unequal resources: Google has massive TPU compute and financial backing, while Generalist, as a startup, must constantly monitor the burn rate imposed by the high costs of data collection.
- Generalist vs Sunday
Compared with Sunday, Generalist can perform highly precise assembly tasks by leveraging high-quality data and precise control. Sunday, however, may be limited by its low-cost glove-based data collection method, which lacks critical force-feedback information, and therefore currently focuses on household tasks with higher tolerance for error.
In terms of commercialization and deployment, Sunday is clearly moving faster. Sunday has explicitly announced plans to launch the "Founding Family Beta" program in late 2026, intending to deploy approximately 50 Memo robots in real households for testing and use.
Generalist and its 270,000-Hour Advantage
Back to All
Robotics is a sector we have followed closely over the long term, and Generalist is one of the very few companies in the robotics field that demonstrates durable competitive potential. Its core strengths are concentrated in data scale, team capabilities, and a clearly defined scaling path.
Looking beyond any single company, we believe that, although robot data remains extremely scarce at present, if model performance can be continuously improved through a combination of human video and real-world robot data, the competitive focus may shift from data scale to data recipe.
The team that first successfully implements and engineers the optimal data recipe may not only achieve a performance lead but also set a demonstrative precedent for the entire industry.
01 Why Generalist?
Generalist has accumulated a large amount of real-world robot data, giving it a 6–12 month lead over other teams.
Currently, methods for collecting robot data can be roughly divided into three categories:
- Real-world data collection, which requires interaction with the physical environment.
1)Teleoperation: Robots are deployed at the front end while humans control them from the back end to complete tasks and collect data. This method achieves the highest data accuracy but is costly and constrained by the number of robots and the available environments.
2)Embodiment-free data collection (UMI): No physical robot is required; humans directly manipulate a gripper or wear an exoskeleton to collect data. Due to issues such as the lack of full-body information, this approach places higher demands on algorithms, particularly relying on high-precision localization and mapping. However, it is more efficient, lower in cost, and better suited for use in complex environments such as outdoors.
- Pure video data collection: Learning relies solely on video data; while the collection cost is low, the data efficiency is relatively limited.
- Synthetic data: Data is generated by constructing simulated environments and automatically producing data based on predefined rules or programs, offering advantages in controllability and scalable generation.
The prevailing view is that training usable robot models still requires real-world data. Real data is not inherently unscalable, but it cannot multiply as easily as in simulation.
A researcher once roughly converted the number of LLM tokens into data duration to draw an analogy between LLMs and the current stage of robotics development:
Assuming a human speech rate of 238 words per minute, with one word roughly equivalent to 1.33 tokens, one hour of human language data corresponds to approximately 19,000 tokens. By this measure, GPT-1 used about 5 billion tokens, equivalent to 270,000 hours of human language data, while the training scale of GPT-3 rises to approximately 15.8 million hours.
Looking further, according to SemiAnalysis, the base training data volume of GPT-4 is approximately 13 trillion tokens, equivalent to about 684 million hours.
Currently, the mainstream scale of real-world robot training data in the industry is around 10,000 hours, meaning that the vast majority of players are still in the "pre-GPT era," and data is extremely scarce within the industry. In this context, Generalist, which claims to have 270,000 hours of training data, may be the only robotics company in the world to have just reached the GPT-1 threshold in terms of data scale.
Moreover, replicating this scale of data is not merely a matter of money but also of time. Another researcher once stated that manufacturing dedicated data collection hardware alone takes 4–6 months, and to replicate 270,000 hours of data would require at least 1,000 people continuously collecting for over half a year to nearly a full year. Consequently, Generalist has a 6–12 month lead over other teams.
The team has a very high talent density and solid technical foundation.
The team possesses a very strong technical capability. The three co-founders combine top-tier academic backgrounds from MIT and Princeton with industry R&D experience at Google DeepMind and Boston Dynamics, and are major contributors to milestone embodied intelligence projects such as PaLM-E and RT-2. They have proven technical experience in the co-design of algorithms and hardware. Moreover, the core members share a long-standing history of academic collaboration and prior entrepreneurial experience together, providing a deep foundation of trust that reduces internal friction and management costs during the early stages of the startup.
In addition, Generalist regards scaling as part of its company DNA. Formerly Head of Engineering at OpenAI, Engineering Lead Evan Morikawa led the engineering teams for ChatGPT, GPT-4, DALL·E, and API products, possessing extensive experience taking projects from 0 to 1 and then to large-scale deployment.
Overall, compared with Physical Intelligence, both Generalist and PI possess top-tier industry capabilities in core algorithmic insights. In terms of team-building strategy, PI leans toward an all-star lineup with more comprehensive member composition, whereas Generalist's team is more streamlined.
A series of demos showcase the models' exceptional dexterity and the team's clear research approach.
Generalist prioritizes dexterity as its top focus in robotics. This commitment is reflected in a series of key milestones: high-frequency dynamic manipulation demonstrated in June 2025, sub-millimeter precision achieved in the LEGO assembly task this September, and GEN-0's advanced capabilities in tool use, deformable object handling, and high-precision assembly. Collectively, these achievements validate the effectiveness of Generalist's methodology for addressing challenges in physical interaction.
Moreover, Generalist's models possess low-level motion generation capabilities: under end-to-end control, they can still produce smooth and precise operational strategies. This ability to enable robots to exhibit dexterity akin to biological instincts in complex environments is currently extremely rare in the market and very difficult to replicate.
Potential Risks
Uncertainty in extrapolation: Does the scaling law hold in the robotics domain?
In November last year, when Generalist released the GEN-0 model it claimed to have validated a scaling law analogous to that of language models for the first time in the robotics domain, whereby downstream task performance exhibits a predictable power-law improvement as pre-training data and compute increase.
If the scaling law does not hold, it would imply a fundamental limitation of deep learning in the physical world, potentially requiring a reevaluation of the valuation logic for the entire embodied intelligence sector. However, the prevailing view leans toward the validity of the scaling law, which implies that the upper limit of intelligence will, to some extent, depend on the ability to collect large-scale data. The forthcoming divergence in development will concern the type of data required.
If foundational models can improve performance through a mix of human video data and real-world robot data, then the competitive factor may no longer be data scale alone, but rather who can first implement the optimal data recipe. The team that first validates and engineers an effective mixed data recipe may not only achieve a performance lead in modeling but also materially advance the evolution of robot training paradigms, setting a demonstrative example for the entire industry.
At present, even with the introduction of human video data, models may still require an equal or even greater amount of real-world robot data to achieve optimal performance. Some researchers even suggest that hardware could account for 70–80% of the value in the robotics field. Therefore, if future robot training continues to rely heavily on large amounts of real-world data, although Generalist has also deployed some hardware for data collection, companies with inherent hardware capabilities such as Tesla and Figure may hold a comparative advantage.
The "GPT-3 moment" for robotics still requires massive amounts of data.
Although Generalist has reached the GPT-1 level (270,000 hours), achieving the equivalent of GPT-3 (15.8 million hours), based on Generalist's current collection rate of 10,000 hours per week, would linearly extrapolate to approximately 30 years. If reaching GPT-3 requires solely real-world data collection, this path may be economically unfeasible for a startup.
This in turn increases the urgency of training models using synthetic data or human video data. If it is later found that models can be sufficiently trained with synthetic or human video data alone, the physical data collection moat established by Generalist could be circumvented.
Lack of commercial use cases.
The robotics industry as a whole currently lacks clear paths to commercialization. Under the premise of self-built data collection hardware and collaboration with Scale AI for annotation, Generalist faces higher cost inputs. At present, the demos publicly showcased by the company remain primarily at the level of stacking LEGO or folding clothes. In contrast, Sunday, which focuses on home environments, is closer to practical deployment.
02 Does Scaling Laws Exist in Robotics?
Early models released by Google, such as PaLM-E and RT-2, produced findings similar to "as model parameters increase, performance and generalization on embodied tasks improve," but Google did not publicly claim to have validated a scaling law in the robotics domain.
In 2024, researchers from MIT and the Technical University of Munich analyzed 327 papers, including models released by Google, and concluded that foundational robot models do exhibit scaling laws, with new robotic capabilities continuously emerging as model scale increases.
In November last year, Generalist claimed to have validated a scaling law analogous to that of language models for the first time in the robotics domain, whereby downstream task performance exhibits a predictable power-law improvement as pre-training data and compute increase. International social media largely regarded this as a significant breakthrough. Ted Xiao, a former Google DeepMind scientist who participated in projects such as Gemini Robotic, RT-2, RT-1, and SayCan, described the result on Twitter as very promising.
Generalist Conclusion 1: Models Phase Transition at 7B
When the Generalist team studied the effect of model parameter size on learning ability, they observed a distinct phase transition phenomenon:
- When the model has a small number of parameters (e.g., at the 1B level), even with massive data input, the training loss stagnates after reaching a certain point. In other words, the model becomes "rigid" and cannot absorb additional information.
- The 6B model begins to benefit from pre-training and demonstrates strong multitask capabilities. When the model is scaled beyond 7B parameters, a phase transition occurs: the large model can continuously absorb data and the training loss keeps decreasing. This indicates that only by crossing this parameter threshold can the model truly acquire general capabilities through pre-training.
Generalist Conclusion 2: Power-Law Between Data Volume and Task Success
Furthermore, at sufficient model scale, there exists a significant power-law relationship between the volume of pre-training data and final performance on downstream tasks, which has been validated both at the level of model metrics and real-world robot experiments.
In terms of model metrics, the team selected model checkpoints trained with varying amounts of pre-training data and performed multitask supervised fine-tuning across 16 different task sets. The results show that the more pre-training data used, the lower the validation loss and next-step action prediction error of the downstream models across all tasks.
In practice, this trend was confirmed on physical robots through blind A/B test. The team ensured that pre-training and post-training data did not overlap in the experiments. The results show that increasing pre-training data improves task success rates: even with only 5.6 hours of downstream data, the gains were substantial. When the full pre-training dataset was combined with sufficient downstream data (550+ hours), task success rates reached their maximum, with peak performance in some scenarios reaching 99%.
Finally, this performance trend was formalized into a predictable mathematical model. Based on the established power-law relationship, the team is able to answer questions such as "how much pre-training data is required to achieve a specific error" or "how much downstream fine-tuning data can be offset by additional pre-training data."
Generalist Conclusion 3: Data Quality & Diversity Trump Volume
The team also compared the impact of different data sources on model performance and found that data quality and diversity matter more than the quantity of data itself: pre-training data from different sources (e.g., different data foundries) can produce models with distinct characteristics depending on the combination used.
For example, some data configurations produced models with both low prediction error and low reverse KL divergence, making them more suitable for supervised fine-tuning. Other configurations, while exhibiting higher prediction error, showed low reverse KL divergence, indicating that the model's output distribution had higher multimodality, which is more advantageous for reinforcement learning.
Research from Physical Intelligence
In the past, due to the significant differences in morphology and movement between human hands and robotic arms, robots found it difficult to learn directly from human video, so typically requiring complex feature alignment processing.
In December 2025, Physical Intelligence demonstrated in Emergence of Human to Robot Transfer in VLAs that, by simply scaling up the pre-training of foundational robot models, the models exhibit the ability to learn from human video:
- In tasks such as sorting eggs by color or organizing a dressing table, the introduction of relevant human data improved the robot's performance by approximately twofold.
- Without large-scale pre-training, the model treats human and robot data as entirely distinct features. As the diversity of robot data in pre-training increases, the model's internal representations of human and robot features begin to align automatically, enabling it to "understand" demonstrations in human video.
To achieve this, the research team employed a co-finetuning strategy using both human and robot data. It should be noted, however, that
- Fine-tuning is not simply a matter of mixing all the data together; rather, human data is combined with the most relevant real-world robot data. For example, in egg-sorting tasks, the robot data provides the basic motor skills of "placing eggs into a carton," while the human data supplements high-level logic demonstrations such as "sorting eggs by color."
- Believed that this proportion both preserves the model's original robotic manipulation capabilities and effectively incorporates human demonstrations, PI used a 1:1 data mixing ratio in the paper. However, the paper did not provide comparative results for other ratios, such as 3:7.
Google's Experience: PaLM-E, RT-2
Generalist's CEO Pete Florence previously led or participated in several major robotics projects at Google, including PaLM-E and RT-2.
PaLM-E validated that as model parameter scale increases, overall performance on embodied tasks continues to improve without exhibiting the catastrophic forgetting commonly seen in traditional multitask learning. At the same time, PaLM-E demonstrated significant positive transfer: training on language and vision tasks (such as Web VQA) not only does not interfere with robot control but actually enhances robotic execution capabilities, reflecting the characteristic of "the more you read, the smarter you work." At sufficiently large model scales, multimodal chain-of-thought capabilities also emerge, enabling the model to perform more complex reasoning across vision, language, and action.
RT-2 further demonstrated improvements in generalization capabilities. Compared with earlier models such as RT-1, which did not transfer semantic reasoning abilities from large-scale network knowledge, RT-2 leverages a VLA architecture with hundreds of billions of parameters, along with joint fine-tuning on multimodal and robot data to exhibit generalization even for previously unseen task instructions.
03 Generalist Puts Model Dexterity First
With the goal of building general-purpose robotic models, Generalist was founded in 2024 and treats scaling AI and robotics as the company's DNA. In the field of robotics, the company places its greatest emphasis on dexterity, which it believes requires breakthroughs across the data, model, and hardware layers. In March 2025, Generalist completed a seed funding round led by Nvidia (NVentures) and Boldstart Ventures.
GEN-0
In November 2025, Generalist released its foundation model GEN-0 and demonstrated the model's integrated capabilities through a long-sequence task:Place the
- cleaning cloth into the box;
- Fold the paper pallet;
- Remove the camera from the plastic bag and take off the protective cover;
- Place the camera precisely into the tray;
- Close the box lid (requiring alignment of small tabs);
- Dispose of the waste (discard the plastic bag).
In completing this task, the model was not provided with step-by-step instructions but instead executed all steps within a single neural network flow, demonstrating its capabilities in deformable object manipulation and high-precision assembly. In addition, GEN-0 also demonstrated cross-embodiment capabilities: the model has been successfully deployed on 6-DoF robotic arms, 7-DoF robotic arms, and semi-humanoid robots with 16+ DoF.
Across social media platforms such as X and Reddit, the public has broadly expressed admiration for GEN-0's dexterity and the level of task precision it can achieve. Stanford robotics professor Shuran Song described the robot's ability to perfectly insert the box lid as satisfying on X.
Demo Before GEN-0
In June of last year, the company published its first blog post, in which the robot was fully autonomous in all demos and controlled in real time by a deep neural network. The network directly maps pixels and other sensor data to 100 Hz action commands, and the blog presented four specific tasks:
- Sorting fasteners: demonstrating the ability to rapidly grasp, reorient, and sort small, flat objects from clutter.
- Folding a box and packaging a bike lock: demonstrating long-sequence capabilities in handling articulated objects (the box) and deformable objects (the chain lock), as well as the millimeter-level precision and force control required in the process.
- Recycling screws: demonstrating tool use and complex bimanual coordination (such as scraping screws off a magnetic bit and bending a paper tray into a funnel).
- Disassembling, sorting, and tossing LEGO bricks: demonstrating strong bimanual coordination (disassembly), regrasping, generalization (recognizing different brick structures and bin position), and high-speed actions (tossing).
Building on the LEGO task demonstrated in June, the company introduced a new internal task for evaluating robotic capabilities: imitation-based construction with LEGO bricks in September. The company cited third-party perspectives that categorize imitation-based LEGO construction as the highest level (Level 4) of general-purpose robotics, namely the ability to perform force-dependent, fine-grained tasks with extremely high precision and to respond subtly to the physical forces of the environment.
Specifically, a human first assembles a small LEGO structure. After which, the robot is able to replicate an identical structure from scratch by observing it. For this task, the company again adopted an end-to-end approach: the model directly ingests visual pixel inputs and generates action commands at 100 Hz, with no task-specific engineering or custom instruction code required. The robot operates entirely by understanding its visual input and executing corresponding actions.
The highlights of these demos are as follows:
- Extremely high dexterity: Assembling LEGO requires sub-millimeter precision, aligning studs correctly and applying the right pressure—far more difficult than disassembly or tossing, as shown in the June demos.
- Visual understanding and imitation: The robot can infer construction goals by observing a human-built structure, rather than merely executing predefined actions.
- Sequential reasoning: It plans each step—selecting the correct block, adjusting orientation, positioning, and assembling—to achieve the final configuration.
- Generalization: Although demos are limited to three-layer structures using 2×4 bricks in four colors, the potential combinations number roughly 99,840. This demonstrates the robot handles diverse structures beyond rote memorization.
04 Technical Barriers of the Generalist: Data, Hardware, and Models
Data Collection
In terms of data volume, GEN-0 used over 270,000 hours of real-world robotic operation data for pre-training, sourced from various activities across thousands of homes, warehouses, and workplaces worldwide. The data feedback loop is also accelerating, currently adding at a rate of 10,000 hours per week.
- How does Generalist collect data?
Generalist uses UMI for data collection, achieving parallel and diverse data gathering by deploying thousands of data collection devices and robots worldwide.
A comment on Reddit mentioned that the company collects data using gloves, with the fingers of the gloves resembling the robotic grippers, allowing humans to wear them while performing everyday chores and tasks. Based on a data collection video released by the company, it is inferred that the wearer has a camera mounted on their head, with each glove also containing a camera.
Generalist also collaborates with multiple data foundries to collect diverse data across different environments. Through continuous A/B testing, they are able to assess the data quality from each partner and adjust the data procurement ratio accordingly.
- How does Generalist process data?
The company has built dedicated hardware and processing pipelines, and even laid dedicated Internet lines, to support high-bandwidth data uploads from various sites to the cloud. This infrastructure allows them to process data equivalent to 6.85 years of human operational experience per day.
- How high are the costs of data collection?
The information report indicates that Generalist's data supplier is Scale AI. The Engineering Lead of 1X stated that Scale AI previously hired college students to label data in the CS field, charging $50 per hour, and then sold it for $200 per hour. Based on this, the data collection cost for Generalist can be roughly estimated.
A comment on X suggests that even in China, collecting the data to train GEN-0 would cost between 2 to 3 million.
Hardware
In addition to the aforementioned data collection hardware, in September of last year, Generalist AI became one of the first eight startups selected for the Physical AI Fellowship program (Fall 2025).
The program launched by MassRobotics in collaboration with AWS and NVIDIA Inception, aims to accelerate the development of startups in the field of Physical AI by providing technical resources. Selected companies primarily receive the following support:
- Technical support from scientists and engineers at the AWS Generative AI Innovation Center.
- $200,000 AWS cloud service credit, along with support from NVIDIA's hardware and software technology stack, and access to software and hardware at discounted prices through the NVIDIA Inception startup program.
- Access to MassRobotics' global robotics partner network.
In addition to Generalist, the first cohort also includes Bedrock Robotics, Blue Water Autonomy, Diligent Robotics, RobCo, Tutor Intelligence, Wandercraft, and Zordi.
Model Architecture
Traditional robotic architectures typically divide the robot model system into system 2 and system 1. Employing a mechanism called Harmonic Reasoning, GEN-0 abandons this separation, which represents an architectural innovation that differentiates GEN-0 from conventional robotic models.
Specifically, this architecture integrates perception tokens and action tokens within the same Transformer stream, enabling the model to "think while acting." It does not need to pause for planning, but can generate continuous, smooth, and intelligent actions at a very high frequency (100 Hz+).
05 Generalist Team
Generalist team members come from institutions such as OpenAI, Boston Dynamics, and Google DeepMind. Prior to joining Generalist, some members participated in the research and release of models like PaLM-E and RT-2, were responsible for scaling ChatGPT and GPT-4 to hundreds of millions of users, or were involved in the development of key autonomous driving technologies and robotic systems such as Atlas, Spot, and Stretch.
- Pete Florence (CEO & Co-founder)
Florence previously served as a Senior Research Scientist at Google DeepMind and earned his PhD from MIT in 2019, during which he focused on vision-guided robotic manipulation and produced representative work such as Dense Object Nets, emphasizing end-to-end learning from raw perception to action. After graduation, he joined Google, where he led or participated in several major robotics projects including PaLM-E and RT-2. In 2024, Florence left Google to found Generalist. Notably, in March of last year, DeepMind cited Florence's co-authored research four times in the Gemini Robotics paper.
- Andrew Barry (CTO & Co-founder)
Andrew Barry previously served at Boston Dynamics, where he was involved in the development of key robotic systems. Andrew and Pete were both students of Russ Tedrake, and their academic collaboration began with research on a lightweight stereoscopic vision-based obstacle avoidance algorithm for drones. Previously, they co-founded the educational workshop Stage One Education, which teaches basic engineering concepts to children in an accessible manner, having reached over ten thousand students.
- Andy Zeng (Chief Scientist & Co-founder)
Andy Zeng previously served as a Research Scientist at Google DeepMind, with a primary focus on robotic grasping and object understanding. He earned his PhD from Princeton University in 2019 and received multiple awards for his research in robotic grasping and visual perception.
His representative work, TossingBot (a system capable of autonomously learning to throw different objects, with Shuran Song as second author) was nominated for the RSS 2019 Best Systems Paper Award. Andy interned at Google as early as 2018 and later joined the company as a core member of the robotics team, working closely with Pete Florence, co-authoring over seventeen papers, and gaining wide attention for research such as "Code as Policies," which enables robots to generate their own code.
- Other members
06 Competitive Landscape
There are numerous startups in the robotics field. If scene complexity is plotted on the vertical axis and delivery format on the horizontal axis, a rough quadrant map of the robotics industry can be drawn. In the past, market attention was primarily focused on the lower half, covering relatively structured environments such as factories and logistics, where task determinacy was higher. With the development of LLMs, market focus has shifted toward the upper half.
- Quadrant I (top right):Consumer-grade general-purpose robots.Sunday — emphasizes practicality, collects data using low-cost gloves, aims for deployment in home environments
- Quadrant II (top left):General-purpose embodied brains.Physical Intelligence — focuses on developing robotic brains, does not produce hardware itself, but engages in hardware partnerships
- Quadrant III (bottom left):Robotic brains for vertical domains.Covariant — started in the logistics sector; in August last year, Amazon reached an agreement, "acquiring" the three co-founders and the core research team
- Quadrant IV (bottom right):Vertical domains via extreme hardware-software integration.Amazon Robotics — focuses on highly customized solutions to maximize efficiency within its own warehouses
Strengths and Weaknesses of Generalist
As a newly established general-purpose robotic brain company, Generalist is positioned in Quadrant II. Overall, Generalist's greatest moat remains its large volume of end-to-end real-world robot data and extremely strong technical team. However, it also faces significant competitive pressure: Physical Intelligence has a more complete team structure and has recently completed substantial funding; Google possesses massive TPU compute resources and financial backing, as well as the ability to leverage the Gemini model; Sunday, meanwhile, achieves faster deployment in home environments.
- Generalist vs Physical Intelligence
Technically, PI's Flow Matching technology can directly output continuous and smooth motor signals, addressing the stiffness in actions caused by discrete tokens in traditional motion generation models (such as Google RT-2). Additionally, PI's Recap algorithm endows the model with self-improvement capabilities, allowing it to increase task throughput and reduce failure rates through expert corrections and autonomous trial-and-error. Generalist currently lacks such a post-deployment "improvement through use" mechanism.
In terms of ecosystem and team building, PI actively cultivates an ecosystem and engages in open collaboration with robotics hardware companies, whereas Generalist's demos are currently limited to desktop operations and lack validation in real production lines. PI's team includes multiple academic luminaries such as Chelsea Finn and Sergey Levine, forming an all-star lineup with a more comprehensive team structure; by comparison, Generalist's team is more streamlined.
Additionally, in November 2025, PI announced the completion of $600 million in funding with a valuation of $5.6 billion, placing it ahead in terms of financing progress.
- Generalist vs Google
In terms of ecosystem, Google has adopted an "Android for Robots"–style open strategy, connecting global laboratories and hardware manufacturers through the Open X-Embodiment Alliance. Generalist, however, lacks Google's ecosystem control to rapidly deploy models across different hardware platforms, and therefore may need to establish sufficiently high barriers in data quality and dexterous manipulation.
Moreover, this is a prolonged battle with unequal resources: Google has massive TPU compute and financial backing, while Generalist, as a startup, must constantly monitor the burn rate imposed by the high costs of data collection.
- Generalist vs Sunday
Compared with Sunday, Generalist can perform highly precise assembly tasks by leveraging high-quality data and precise control. Sunday, however, may be limited by its low-cost glove-based data collection method, which lacks critical force-feedback information, and therefore currently focuses on household tasks with higher tolerance for error.
In terms of commercialization and deployment, Sunday is clearly moving faster. Sunday has explicitly announced plans to launch the "Founding Family Beta" program in late 2026, intending to deploy approximately 50 Memo robots in real households for testing and use.
Generalist and its 270,000-Hour Advantage
Back to All
Robotics is a sector we have followed closely over the long term, and Generalist is one of the very few companies in the robotics field that demonstrates durable competitive potential. Its core strengths are concentrated in data scale, team capabilities, and a clearly defined scaling path.
Looking beyond any single company, we believe that, although robot data remains extremely scarce at present, if model performance can be continuously improved through a combination of human video and real-world robot data, the competitive focus may shift from data scale to data recipe.
The team that first successfully implements and engineers the optimal data recipe may not only achieve a performance lead but also set a demonstrative precedent for the entire industry.
01 Why Generalist?
Generalist has accumulated a large amount of real-world robot data, giving it a 6–12 month lead over other teams.
Currently, methods for collecting robot data can be roughly divided into three categories:
- Real-world data collection, which requires interaction with the physical environment.
1)Teleoperation: Robots are deployed at the front end while humans control them from the back end to complete tasks and collect data. This method achieves the highest data accuracy but is costly and constrained by the number of robots and the available environments.
2)Embodiment-free data collection (UMI): No physical robot is required; humans directly manipulate a gripper or wear an exoskeleton to collect data. Due to issues such as the lack of full-body information, this approach places higher demands on algorithms, particularly relying on high-precision localization and mapping. However, it is more efficient, lower in cost, and better suited for use in complex environments such as outdoors.
- Pure video data collection: Learning relies solely on video data; while the collection cost is low, the data efficiency is relatively limited.
- Synthetic data: Data is generated by constructing simulated environments and automatically producing data based on predefined rules or programs, offering advantages in controllability and scalable generation.
The prevailing view is that training usable robot models still requires real-world data. Real data is not inherently unscalable, but it cannot multiply as easily as in simulation.
A researcher once roughly converted the number of LLM tokens into data duration to draw an analogy between LLMs and the current stage of robotics development:
Assuming a human speech rate of 238 words per minute, with one word roughly equivalent to 1.33 tokens, one hour of human language data corresponds to approximately 19,000 tokens. By this measure, GPT-1 used about 5 billion tokens, equivalent to 270,000 hours of human language data, while the training scale of GPT-3 rises to approximately 15.8 million hours.
Looking further, according to SemiAnalysis, the base training data volume of GPT-4 is approximately 13 trillion tokens, equivalent to about 684 million hours.
Currently, the mainstream scale of real-world robot training data in the industry is around 10,000 hours, meaning that the vast majority of players are still in the "pre-GPT era," and data is extremely scarce within the industry. In this context, Generalist, which claims to have 270,000 hours of training data, may be the only robotics company in the world to have just reached the GPT-1 threshold in terms of data scale.
Moreover, replicating this scale of data is not merely a matter of money but also of time. Another researcher once stated that manufacturing dedicated data collection hardware alone takes 4–6 months, and to replicate 270,000 hours of data would require at least 1,000 people continuously collecting for over half a year to nearly a full year. Consequently, Generalist has a 6–12 month lead over other teams.
The team has a very high talent density and solid technical foundation.
The team possesses a very strong technical capability. The three co-founders combine top-tier academic backgrounds from MIT and Princeton with industry R&D experience at Google DeepMind and Boston Dynamics, and are major contributors to milestone embodied intelligence projects such as PaLM-E and RT-2. They have proven technical experience in the co-design of algorithms and hardware. Moreover, the core members share a long-standing history of academic collaboration and prior entrepreneurial experience together, providing a deep foundation of trust that reduces internal friction and management costs during the early stages of the startup.
In addition, Generalist regards scaling as part of its company DNA. Formerly Head of Engineering at OpenAI, Engineering Lead Evan Morikawa led the engineering teams for ChatGPT, GPT-4, DALL·E, and API products, possessing extensive experience taking projects from 0 to 1 and then to large-scale deployment.
Overall, compared with Physical Intelligence, both Generalist and PI possess top-tier industry capabilities in core algorithmic insights. In terms of team-building strategy, PI leans toward an all-star lineup with more comprehensive member composition, whereas Generalist's team is more streamlined.
A series of demos showcase the models' exceptional dexterity and the team's clear research approach.
Generalist prioritizes dexterity as its top focus in robotics. This commitment is reflected in a series of key milestones: high-frequency dynamic manipulation demonstrated in June 2025, sub-millimeter precision achieved in the LEGO assembly task this September, and GEN-0's advanced capabilities in tool use, deformable object handling, and high-precision assembly. Collectively, these achievements validate the effectiveness of Generalist's methodology for addressing challenges in physical interaction.
Moreover, Generalist's models possess low-level motion generation capabilities: under end-to-end control, they can still produce smooth and precise operational strategies. This ability to enable robots to exhibit dexterity akin to biological instincts in complex environments is currently extremely rare in the market and very difficult to replicate.
Potential Risks
Uncertainty in extrapolation: Does the scaling law hold in the robotics domain?
In November last year, when Generalist released the GEN-0 model it claimed to have validated a scaling law analogous to that of language models for the first time in the robotics domain, whereby downstream task performance exhibits a predictable power-law improvement as pre-training data and compute increase.
If the scaling law does not hold, it would imply a fundamental limitation of deep learning in the physical world, potentially requiring a reevaluation of the valuation logic for the entire embodied intelligence sector. However, the prevailing view leans toward the validity of the scaling law, which implies that the upper limit of intelligence will, to some extent, depend on the ability to collect large-scale data. The forthcoming divergence in development will concern the type of data required.
If foundational models can improve performance through a mix of human video data and real-world robot data, then the competitive factor may no longer be data scale alone, but rather who can first implement the optimal data recipe. The team that first validates and engineers an effective mixed data recipe may not only achieve a performance lead in modeling but also materially advance the evolution of robot training paradigms, setting a demonstrative example for the entire industry.
At present, even with the introduction of human video data, models may still require an equal or even greater amount of real-world robot data to achieve optimal performance. Some researchers even suggest that hardware could account for 70–80% of the value in the robotics field. Therefore, if future robot training continues to rely heavily on large amounts of real-world data, although Generalist has also deployed some hardware for data collection, companies with inherent hardware capabilities such as Tesla and Figure may hold a comparative advantage.
The "GPT-3 moment" for robotics still requires massive amounts of data.
Although Generalist has reached the GPT-1 level (270,000 hours), achieving the equivalent of GPT-3 (15.8 million hours), based on Generalist's current collection rate of 10,000 hours per week, would linearly extrapolate to approximately 30 years. If reaching GPT-3 requires solely real-world data collection, this path may be economically unfeasible for a startup.
This in turn increases the urgency of training models using synthetic data or human video data. If it is later found that models can be sufficiently trained with synthetic or human video data alone, the physical data collection moat established by Generalist could be circumvented.
Lack of commercial use cases.
The robotics industry as a whole currently lacks clear paths to commercialization. Under the premise of self-built data collection hardware and collaboration with Scale AI for annotation, Generalist faces higher cost inputs. At present, the demos publicly showcased by the company remain primarily at the level of stacking LEGO or folding clothes. In contrast, Sunday, which focuses on home environments, is closer to practical deployment.
02 Does Scaling Laws Exist in Robotics?
Early models released by Google, such as PaLM-E and RT-2, produced findings similar to "as model parameters increase, performance and generalization on embodied tasks improve," but Google did not publicly claim to have validated a scaling law in the robotics domain.
In 2024, researchers from MIT and the Technical University of Munich analyzed 327 papers, including models released by Google, and concluded that foundational robot models do exhibit scaling laws, with new robotic capabilities continuously emerging as model scale increases.
In November last year, Generalist claimed to have validated a scaling law analogous to that of language models for the first time in the robotics domain, whereby downstream task performance exhibits a predictable power-law improvement as pre-training data and compute increase. International social media largely regarded this as a significant breakthrough. Ted Xiao, a former Google DeepMind scientist who participated in projects such as Gemini Robotic, RT-2, RT-1, and SayCan, described the result on Twitter as very promising.
Generalist Conclusion 1: Models Phase Transition at 7B
When the Generalist team studied the effect of model parameter size on learning ability, they observed a distinct phase transition phenomenon:
- When the model has a small number of parameters (e.g., at the 1B level), even with massive data input, the training loss stagnates after reaching a certain point. In other words, the model becomes "rigid" and cannot absorb additional information.
- The 6B model begins to benefit from pre-training and demonstrates strong multitask capabilities. When the model is scaled beyond 7B parameters, a phase transition occurs: the large model can continuously absorb data and the training loss keeps decreasing. This indicates that only by crossing this parameter threshold can the model truly acquire general capabilities through pre-training.
Generalist Conclusion 2: Power-Law Between Data Volume and Task Success
Furthermore, at sufficient model scale, there exists a significant power-law relationship between the volume of pre-training data and final performance on downstream tasks, which has been validated both at the level of model metrics and real-world robot experiments.
In terms of model metrics, the team selected model checkpoints trained with varying amounts of pre-training data and performed multitask supervised fine-tuning across 16 different task sets. The results show that the more pre-training data used, the lower the validation loss and next-step action prediction error of the downstream models across all tasks.
In practice, this trend was confirmed on physical robots through blind A/B test. The team ensured that pre-training and post-training data did not overlap in the experiments. The results show that increasing pre-training data improves task success rates: even with only 5.6 hours of downstream data, the gains were substantial. When the full pre-training dataset was combined with sufficient downstream data (550+ hours), task success rates reached their maximum, with peak performance in some scenarios reaching 99%.
Finally, this performance trend was formalized into a predictable mathematical model. Based on the established power-law relationship, the team is able to answer questions such as "how much pre-training data is required to achieve a specific error" or "how much downstream fine-tuning data can be offset by additional pre-training data."
Generalist Conclusion 3: Data Quality & Diversity Trump Volume
The team also compared the impact of different data sources on model performance and found that data quality and diversity matter more than the quantity of data itself: pre-training data from different sources (e.g., different data foundries) can produce models with distinct characteristics depending on the combination used.
For example, some data configurations produced models with both low prediction error and low reverse KL divergence, making them more suitable for supervised fine-tuning. Other configurations, while exhibiting higher prediction error, showed low reverse KL divergence, indicating that the model's output distribution had higher multimodality, which is more advantageous for reinforcement learning.
Research from Physical Intelligence
In the past, due to the significant differences in morphology and movement between human hands and robotic arms, robots found it difficult to learn directly from human video, so typically requiring complex feature alignment processing.
In December 2025, Physical Intelligence demonstrated in Emergence of Human to Robot Transfer in VLAs that, by simply scaling up the pre-training of foundational robot models, the models exhibit the ability to learn from human video:
- In tasks such as sorting eggs by color or organizing a dressing table, the introduction of relevant human data improved the robot's performance by approximately twofold.
- Without large-scale pre-training, the model treats human and robot data as entirely distinct features. As the diversity of robot data in pre-training increases, the model's internal representations of human and robot features begin to align automatically, enabling it to "understand" demonstrations in human video.
To achieve this, the research team employed a co-finetuning strategy using both human and robot data. It should be noted, however, that
- Fine-tuning is not simply a matter of mixing all the data together; rather, human data is combined with the most relevant real-world robot data. For example, in egg-sorting tasks, the robot data provides the basic motor skills of "placing eggs into a carton," while the human data supplements high-level logic demonstrations such as "sorting eggs by color."
- Believed that this proportion both preserves the model's original robotic manipulation capabilities and effectively incorporates human demonstrations, PI used a 1:1 data mixing ratio in the paper. However, the paper did not provide comparative results for other ratios, such as 3:7.
Google's Experience: PaLM-E, RT-2
Generalist's CEO Pete Florence previously led or participated in several major robotics projects at Google, including PaLM-E and RT-2.
PaLM-E validated that as model parameter scale increases, overall performance on embodied tasks continues to improve without exhibiting the catastrophic forgetting commonly seen in traditional multitask learning. At the same time, PaLM-E demonstrated significant positive transfer: training on language and vision tasks (such as Web VQA) not only does not interfere with robot control but actually enhances robotic execution capabilities, reflecting the characteristic of "the more you read, the smarter you work." At sufficiently large model scales, multimodal chain-of-thought capabilities also emerge, enabling the model to perform more complex reasoning across vision, language, and action.
RT-2 further demonstrated improvements in generalization capabilities. Compared with earlier models such as RT-1, which did not transfer semantic reasoning abilities from large-scale network knowledge, RT-2 leverages a VLA architecture with hundreds of billions of parameters, along with joint fine-tuning on multimodal and robot data to exhibit generalization even for previously unseen task instructions.
03 Generalist Puts Model Dexterity First
With the goal of building general-purpose robotic models, Generalist was founded in 2024 and treats scaling AI and robotics as the company's DNA. In the field of robotics, the company places its greatest emphasis on dexterity, which it believes requires breakthroughs across the data, model, and hardware layers. In March 2025, Generalist completed a seed funding round led by Nvidia (NVentures) and Boldstart Ventures.
GEN-0
In November 2025, Generalist released its foundation model GEN-0 and demonstrated the model's integrated capabilities through a long-sequence task:Place the
- cleaning cloth into the box;
- Fold the paper pallet;
- Remove the camera from the plastic bag and take off the protective cover;
- Place the camera precisely into the tray;
- Close the box lid (requiring alignment of small tabs);
- Dispose of the waste (discard the plastic bag).
In completing this task, the model was not provided with step-by-step instructions but instead executed all steps within a single neural network flow, demonstrating its capabilities in deformable object manipulation and high-precision assembly. In addition, GEN-0 also demonstrated cross-embodiment capabilities: the model has been successfully deployed on 6-DoF robotic arms, 7-DoF robotic arms, and semi-humanoid robots with 16+ DoF.
Across social media platforms such as X and Reddit, the public has broadly expressed admiration for GEN-0's dexterity and the level of task precision it can achieve. Stanford robotics professor Shuran Song described the robot's ability to perfectly insert the box lid as satisfying on X.
Demo Before GEN-0
In June of last year, the company published its first blog post, in which the robot was fully autonomous in all demos and controlled in real time by a deep neural network. The network directly maps pixels and other sensor data to 100 Hz action commands, and the blog presented four specific tasks:
- Sorting fasteners: demonstrating the ability to rapidly grasp, reorient, and sort small, flat objects from clutter.
- Folding a box and packaging a bike lock: demonstrating long-sequence capabilities in handling articulated objects (the box) and deformable objects (the chain lock), as well as the millimeter-level precision and force control required in the process.
- Recycling screws: demonstrating tool use and complex bimanual coordination (such as scraping screws off a magnetic bit and bending a paper tray into a funnel).
- Disassembling, sorting, and tossing LEGO bricks: demonstrating strong bimanual coordination (disassembly), regrasping, generalization (recognizing different brick structures and bin position), and high-speed actions (tossing).
Building on the LEGO task demonstrated in June, the company introduced a new internal task for evaluating robotic capabilities: imitation-based construction with LEGO bricks in September. The company cited third-party perspectives that categorize imitation-based LEGO construction as the highest level (Level 4) of general-purpose robotics, namely the ability to perform force-dependent, fine-grained tasks with extremely high precision and to respond subtly to the physical forces of the environment.
Specifically, a human first assembles a small LEGO structure. After which, the robot is able to replicate an identical structure from scratch by observing it. For this task, the company again adopted an end-to-end approach: the model directly ingests visual pixel inputs and generates action commands at 100 Hz, with no task-specific engineering or custom instruction code required. The robot operates entirely by understanding its visual input and executing corresponding actions.
The highlights of these demos are as follows:
- Extremely high dexterity: Assembling LEGO requires sub-millimeter precision, aligning studs correctly and applying the right pressure—far more difficult than disassembly or tossing, as shown in the June demos.
- Visual understanding and imitation: The robot can infer construction goals by observing a human-built structure, rather than merely executing predefined actions.
- Sequential reasoning: It plans each step—selecting the correct block, adjusting orientation, positioning, and assembling—to achieve the final configuration.
- Generalization: Although demos are limited to three-layer structures using 2×4 bricks in four colors, the potential combinations number roughly 99,840. This demonstrates the robot handles diverse structures beyond rote memorization.
04 Technical Barriers of the Generalist: Data, Hardware, and Models
Data Collection
In terms of data volume, GEN-0 used over 270,000 hours of real-world robotic operation data for pre-training, sourced from various activities across thousands of homes, warehouses, and workplaces worldwide. The data feedback loop is also accelerating, currently adding at a rate of 10,000 hours per week.
- How does Generalist collect data?
Generalist uses UMI for data collection, achieving parallel and diverse data gathering by deploying thousands of data collection devices and robots worldwide.
A comment on Reddit mentioned that the company collects data using gloves, with the fingers of the gloves resembling the robotic grippers, allowing humans to wear them while performing everyday chores and tasks. Based on a data collection video released by the company, it is inferred that the wearer has a camera mounted on their head, with each glove also containing a camera.
Generalist also collaborates with multiple data foundries to collect diverse data across different environments. Through continuous A/B testing, they are able to assess the data quality from each partner and adjust the data procurement ratio accordingly.
- How does Generalist process data?
The company has built dedicated hardware and processing pipelines, and even laid dedicated Internet lines, to support high-bandwidth data uploads from various sites to the cloud. This infrastructure allows them to process data equivalent to 6.85 years of human operational experience per day.
- How high are the costs of data collection?
The information report indicates that Generalist's data supplier is Scale AI. The Engineering Lead of 1X stated that Scale AI previously hired college students to label data in the CS field, charging $50 per hour, and then sold it for $200 per hour. Based on this, the data collection cost for Generalist can be roughly estimated.
A comment on X suggests that even in China, collecting the data to train GEN-0 would cost between 2 to 3 million.
Hardware
In addition to the aforementioned data collection hardware, in September of last year, Generalist AI became one of the first eight startups selected for the Physical AI Fellowship program (Fall 2025).
The program launched by MassRobotics in collaboration with AWS and NVIDIA Inception, aims to accelerate the development of startups in the field of Physical AI by providing technical resources. Selected companies primarily receive the following support:
- Technical support from scientists and engineers at the AWS Generative AI Innovation Center.
- $200,000 AWS cloud service credit, along with support from NVIDIA's hardware and software technology stack, and access to software and hardware at discounted prices through the NVIDIA Inception startup program.
- Access to MassRobotics' global robotics partner network.
In addition to Generalist, the first cohort also includes Bedrock Robotics, Blue Water Autonomy, Diligent Robotics, RobCo, Tutor Intelligence, Wandercraft, and Zordi.
Model Architecture
Traditional robotic architectures typically divide the robot model system into system 2 and system 1. Employing a mechanism called Harmonic Reasoning, GEN-0 abandons this separation, which represents an architectural innovation that differentiates GEN-0 from conventional robotic models.
Specifically, this architecture integrates perception tokens and action tokens within the same Transformer stream, enabling the model to "think while acting." It does not need to pause for planning, but can generate continuous, smooth, and intelligent actions at a very high frequency (100 Hz+).
05 Generalist Team
Generalist team members come from institutions such as OpenAI, Boston Dynamics, and Google DeepMind. Prior to joining Generalist, some members participated in the research and release of models like PaLM-E and RT-2, were responsible for scaling ChatGPT and GPT-4 to hundreds of millions of users, or were involved in the development of key autonomous driving technologies and robotic systems such as Atlas, Spot, and Stretch.
- Pete Florence (CEO & Co-founder)
Florence previously served as a Senior Research Scientist at Google DeepMind and earned his PhD from MIT in 2019, during which he focused on vision-guided robotic manipulation and produced representative work such as Dense Object Nets, emphasizing end-to-end learning from raw perception to action. After graduation, he joined Google, where he led or participated in several major robotics projects including PaLM-E and RT-2. In 2024, Florence left Google to found Generalist. Notably, in March of last year, DeepMind cited Florence's co-authored research four times in the Gemini Robotics paper.
- Andrew Barry (CTO & Co-founder)
Andrew Barry previously served at Boston Dynamics, where he was involved in the development of key robotic systems. Andrew and Pete were both students of Russ Tedrake, and their academic collaboration began with research on a lightweight stereoscopic vision-based obstacle avoidance algorithm for drones. Previously, they co-founded the educational workshop Stage One Education, which teaches basic engineering concepts to children in an accessible manner, having reached over ten thousand students.
- Andy Zeng (Chief Scientist & Co-founder)
Andy Zeng previously served as a Research Scientist at Google DeepMind, with a primary focus on robotic grasping and object understanding. He earned his PhD from Princeton University in 2019 and received multiple awards for his research in robotic grasping and visual perception.
His representative work, TossingBot (a system capable of autonomously learning to throw different objects, with Shuran Song as second author) was nominated for the RSS 2019 Best Systems Paper Award. Andy interned at Google as early as 2018 and later joined the company as a core member of the robotics team, working closely with Pete Florence, co-authoring over seventeen papers, and gaining wide attention for research such as "Code as Policies," which enables robots to generate their own code.
- Other members
06 Competitive Landscape
There are numerous startups in the robotics field. If scene complexity is plotted on the vertical axis and delivery format on the horizontal axis, a rough quadrant map of the robotics industry can be drawn. In the past, market attention was primarily focused on the lower half, covering relatively structured environments such as factories and logistics, where task determinacy was higher. With the development of LLMs, market focus has shifted toward the upper half.
- Quadrant I (top right):Consumer-grade general-purpose robots.Sunday — emphasizes practicality, collects data using low-cost gloves, aims for deployment in home environments
- Quadrant II (top left):General-purpose embodied brains.Physical Intelligence — focuses on developing robotic brains, does not produce hardware itself, but engages in hardware partnerships
- Quadrant III (bottom left):Robotic brains for vertical domains.Covariant — started in the logistics sector; in August last year, Amazon reached an agreement, "acquiring" the three co-founders and the core research team
- Quadrant IV (bottom right):Vertical domains via extreme hardware-software integration.Amazon Robotics — focuses on highly customized solutions to maximize efficiency within its own warehouses
Strengths and Weaknesses of Generalist
As a newly established general-purpose robotic brain company, Generalist is positioned in Quadrant II. Overall, Generalist's greatest moat remains its large volume of end-to-end real-world robot data and extremely strong technical team. However, it also faces significant competitive pressure: Physical Intelligence has a more complete team structure and has recently completed substantial funding; Google possesses massive TPU compute resources and financial backing, as well as the ability to leverage the Gemini model; Sunday, meanwhile, achieves faster deployment in home environments.
- Generalist vs Physical Intelligence
Technically, PI's Flow Matching technology can directly output continuous and smooth motor signals, addressing the stiffness in actions caused by discrete tokens in traditional motion generation models (such as Google RT-2). Additionally, PI's Recap algorithm endows the model with self-improvement capabilities, allowing it to increase task throughput and reduce failure rates through expert corrections and autonomous trial-and-error. Generalist currently lacks such a post-deployment "improvement through use" mechanism.
In terms of ecosystem and team building, PI actively cultivates an ecosystem and engages in open collaboration with robotics hardware companies, whereas Generalist's demos are currently limited to desktop operations and lack validation in real production lines. PI's team includes multiple academic luminaries such as Chelsea Finn and Sergey Levine, forming an all-star lineup with a more comprehensive team structure; by comparison, Generalist's team is more streamlined.
Additionally, in November 2025, PI announced the completion of $600 million in funding with a valuation of $5.6 billion, placing it ahead in terms of financing progress.
- Generalist vs Google
In terms of ecosystem, Google has adopted an "Android for Robots"–style open strategy, connecting global laboratories and hardware manufacturers through the Open X-Embodiment Alliance. Generalist, however, lacks Google's ecosystem control to rapidly deploy models across different hardware platforms, and therefore may need to establish sufficiently high barriers in data quality and dexterous manipulation.
Moreover, this is a prolonged battle with unequal resources: Google has massive TPU compute and financial backing, while Generalist, as a startup, must constantly monitor the burn rate imposed by the high costs of data collection.
- Generalist vs Sunday
Compared with Sunday, Generalist can perform highly precise assembly tasks by leveraging high-quality data and precise control. Sunday, however, may be limited by its low-cost glove-based data collection method, which lacks critical force-feedback information, and therefore currently focuses on household tasks with higher tolerance for error.
In terms of commercialization and deployment, Sunday is clearly moving faster. Sunday has explicitly announced plans to launch the "Founding Family Beta" program in late 2026, intending to deploy approximately 50 Memo robots in real households for testing and use.