


Beyond DeepSeek: What China's Model Builders Are Seeing
<<< Back to All
3 of the top five most-popular models on OpenRouter’s LLM Ranking were developed by Chinese AI lab. Across the developer community, Chinese models have stopped being the “also-ran” story and started being the story.
We’ve been tracking China’s model ecosystem closely. After the Lunar New Year releases landed , Seedance 2.0(&Seed2.0), GLM-5, and MiniMax M2.5, we wanted to go beyond the benchmarks and the press releases. So we organized a closed-door discussion inside our Best Ideas community.
The session brought together a mix of voices: researchers from Zhipu, MiniMax, and ByteDance who are building these models, alongside developers and practitioners who are deploying them in production. What follows reflects the full conversation — not any single participant’s view.
Some of them confirmed what we expected. A lot of it didn’t.
This analysis and these judgments were compiled from a collective Best Ideas community discussion.
Seedance 2.0: For the first time, a Chinese model isn’t catching up — it’s leading
The framing that matters most about Seedance 2.0 isn’t technical — it’s historic. For the first time, a Chinese foundation model isn’t just competitive globally, it’s decisively ahead.
In video generation, the consensus in the room was that Seedance 2.0 stands at least a generation in front of Sora 2 and Veo 3. This isn’t a claim about catching up. It’s a claim about leading.
What makes that lead meaningful is where it lands: efficiency and usability, not just quality scores.
Seedance collapses the gap between idea and output in ways that restructure the economics of content creation entirely.
For non-professional creators, a full day of iteration compresses into thirty minutes. At that ratio, the traditional grammar of film and TV production, its workflows, budgets, and gatekeepers, doesn’t just become less relevant. It becomes a relic.
The room’s projection: within 6 to 12 months, for under $14, an ordinary person could plausibly produce a 30-40 minute film at Netflix-level image quality. The supply of content won’t just grow — it will compound.
The disruption runs in two directions:
- First, it is reshaping existing industries, film, games, advertising, where the cost structure of production is about to be repriced.
- Secondly, it is unlocking of scenarios that simply couldn’t exist before: real-time generated interactive video, AI companionship experiences, entirely new forms of social interaction built on personalized visual content.
Apprantly, the latter one looks more exciting to the community.
The shift from lottery to reliability is what makes this real. Older video models operated on what participants called a “roulette dynamic”: generate an eight-second clip, get three or four usable seconds, reroll. Seedance 2.0 broke that pattern. A single 15s-generation now largely meets commercial standards for semantic consistency and shot continuity — cinematic pacing, micro-expressions, the physical logic of how one shot leads into the next.
Video creation has moved from a roulette dynamic to something industrial-grade.
The discussion was direct about why ByteDance’s lead here is likely to persist. It’s not just compute or data. It’s organizational depth.
ByteDance appears to operate on what might be called a “three-generation” model cadence: one generation in live optimization, one in core development, and one in forward-looking research — a depth of parallel iteration that most peers, domestic and international, can barely sustain two of.
The downstream consequence that surprised us most: the teams under the most pressure right now aren’t incumbent video studios. It’s the workflow tool builders — the products that stitched together Midjourney for images, ElevenLabs for voice, and editing software into a chain. End-to-end models are quietly swallowing that stack.
MiniMax: The architecture is a commercial thesis, not a technical one
MiniMax M2’s parameter count — 200B total, 10B activated — is unusual enough that it raised eyebrows across the industry. The MiniMax team was direct about the reasoning: the sizing decision wasn’t a capability trade-off. It was a bet on how agents will actually be deployed.
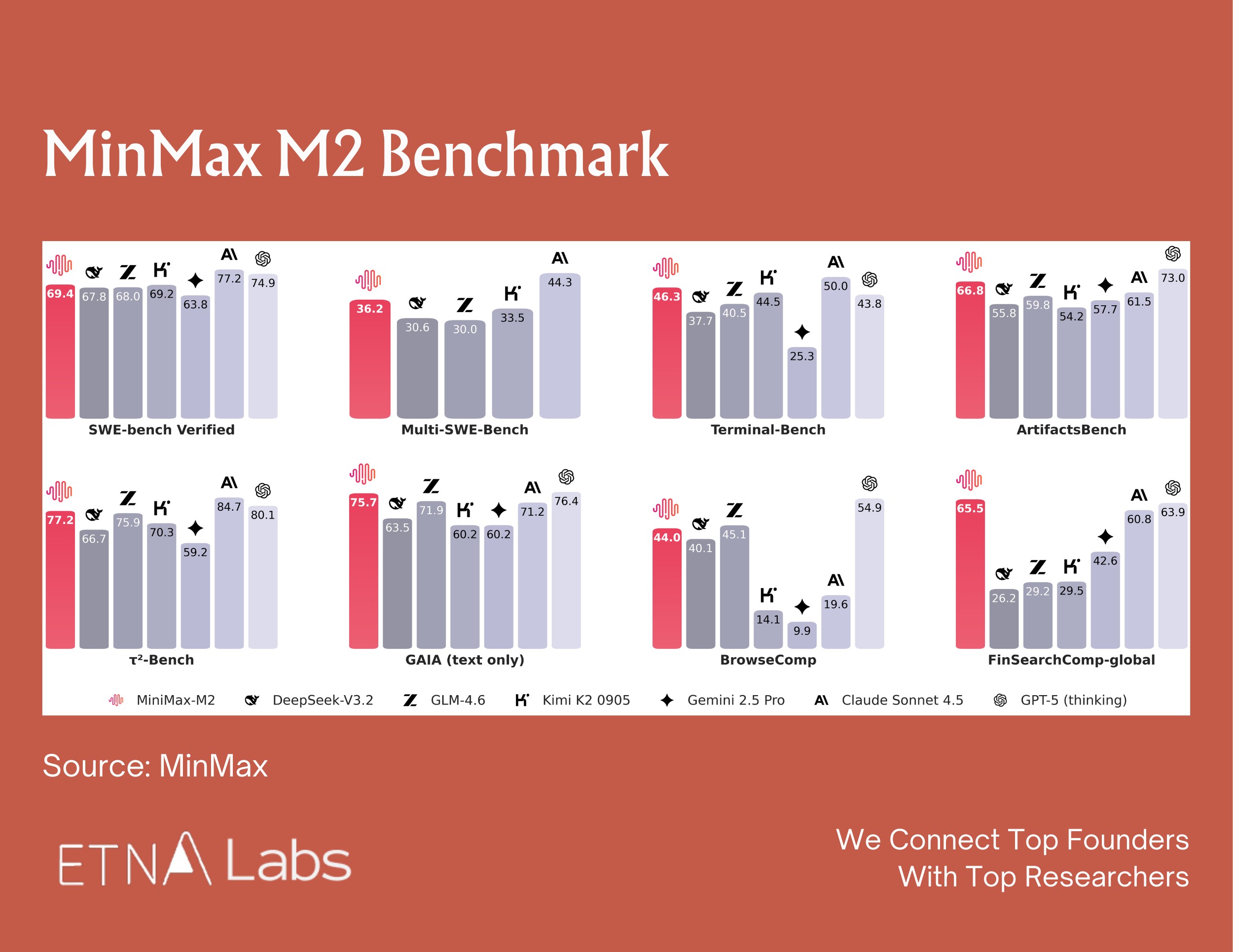
In real agentic workflows, users run five to ten agents in parallel. Latency shapes productivity as much as raw capability. And as agents migrate from developers to mainstream users, they become 24/7 personal assistants — always-on, high-frequency, generating enormous token volumes.
At those usage densities, frontier pricing becomes structurally unsustainable. They pointed to Talkie — MiniMax’s companion AI product — as the proof of concept: wide audience, long conversation threads, extreme usage density. The M2-her model powering Talkie(MiniMax’s companion AI app) is a post-trained variant built on the M2 base.
The implicit critique of the broader industry is sharp: a model that tops every benchmark but prices itself out of agentic deployment isn’t winning the market. It’s winning a leaderboard.
MiniMax also shared the internal benchmark they built to evaluate the coding capability — VIBE Bench — which spans the full stack of real-world software development, including cloud configuration, multi-language environments, and API integrations.
Their view on standard benchmarks was pointed: SWE-style evaluations are too narrow (focused mostly on bug fixes) and too language-homogeneous (skewing Python and TypeScript, while production systems run Go, C++, Rust).
According to their internal testing, MiniMax M2 shows significant improvements over Claude Opus on the VIBE leaderboard.
The lesson the MiniMax team kept coming back to was Anthropic’s approach to dogfooding.
They’ve moved the entire company — including legal and HR — into an agent-native operating model. If agents fail at a task internally, that failure gets formalized as the next benchmark. It’s a feedback loop they believe is the actual reason Anthropic has been able to maintain both model depth and product quality — and where it genuinely leads most domestic players.
GLM-5: Benchmarking against Anthropic, not the leaderboard
There was an internal strategic debate at Zhipu AI that came up in the conversation. One path: chase top scores in math and coding competitions, optimize for reasoning benchmarks, build toward long-horizon scientific research. The other path: prioritize economically valuable productivity tasks — real-world programming workflows, agentic problem-solving.
Zhipu’s researchers chose the second, and chose Anthropic as the explicit benchmark.
The reasoning they laid out is worth unpacking. Coding and agent tasks aren’t just harder versions of reasoning tasks — they’re structurally different. Reasoning operates within a bounded problem space where heavy thinking, and reinforcement learning alone, can produce high scores. Complex coding requires something closer to engineering intuition: identifying root causes quickly, resolving issues with minimal token usage rather than trial and error. That kind of intuition, they found experimentally, scales with model size in ways that reasoning benchmarks don’t fully capture.
GLM-5 runs at 744B total parameters with roughly 40B activated per inference — deliberately constrained to fit within a standard 8-GPU cluster, keeping it viable for real-world production deployment. (Notably, GLM-5 was trained and runs inference entirely on Huawei Ascend chips, with no dependency on NVIDIA hardware — a geopolitical statement as much as a technical one.)
The model also introduces DSA (DeepSeek Sparse Attention) to handle long-context coding workloads, where input context regularly dwarfs generated output.
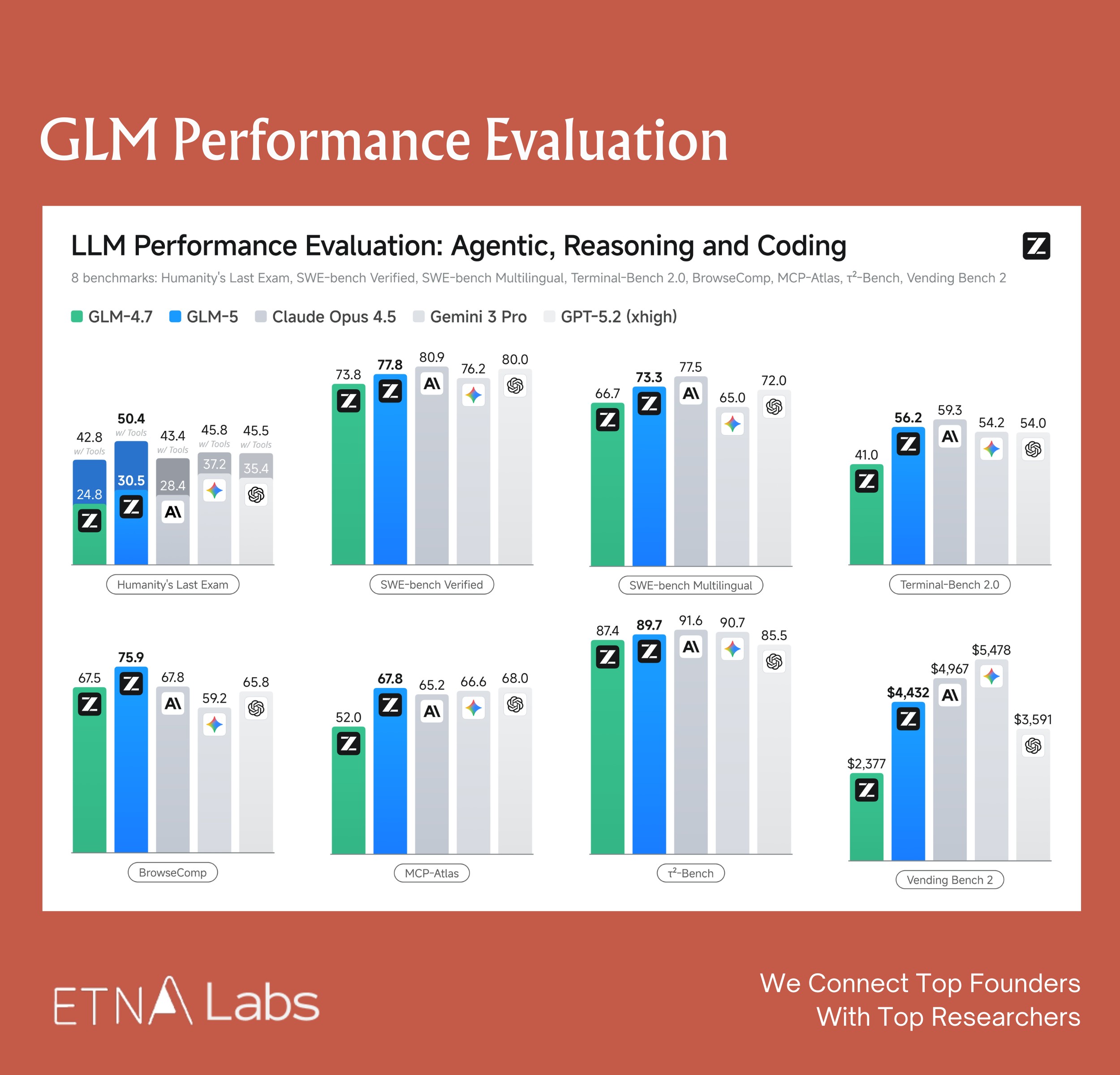
The competitive positioning Zhipu’s team laid out is explicit: Anthropic currently dominates the high end of the coding market at $15-25 per million tokens. GLM-5 is targeting the upper-middle segment at roughly $3 — a price gap significant enough that even developers deeply embedded in Claude’s tooling ecosystem are paying attention. Domestic open-source models have also maintained strong compatibility with Claude skills and related tooling, making switching relatively seamless.
What this means for the broader picture
A few things from the conversation that didn’t fit neatly into any single company’s story:
Data is becoming the real moat, not compute.
Multiple participants pointed to this independently. The paradigm is shifting from compute-bound to data-bound — not because compute isn’t scarce, but because it’s becoming more accessible. The edge increasingly lives in data acquisition, cleaning, long-tail mining, and evaluation loops. Seedance 2.0’s lead in video generation, for instance, is inseparable from fine-grained work on tail-end video data. And China has structural advantages here that are underappreciated: a deep ecosystem of small, agile video production teams capable of capturing proprietary footage at scale.
Hardware scarcity is driving architecture-level innovation.
Chinese companies are working under tighter GPU constraints than their Silicon Valley counterparts. Several researchers noted that this is producing more architectural creativity at the inference layer — necessity forcing efficiency work that well-resourced labs have little incentive to do.
The market won’t consolidate to one winner.
The consensus in the room was that the AI market will look less like search (9:1 winner-take-all) and more like e-commerce — multiple players finding durable niches through different product sensibilities and user relationships. When model capabilities converge, the differentiation shifts to taste: do you build a maximally efficient tool, or a product with genuine personality?
The question we’re sitting with
We framed 2026 as a structural inflection point, not an incremental one. The Lunar New Year releases were the opening move. By mid-year, new long-horizon reasoning models and async agent frameworks are expected to enter. Every industry is showing up with real deployment use cases.
The harder question — one the room didn’t fully resolve — is what happens to the application layer. Agent capabilities are increasingly being driven by base model improvements, which means orchestration logic and system prompt design that once belonged to application developers is getting absorbed into the model itself. Kimi 2.5 reportedly baked an orchestrator-plus-subagent architecture directly into the model via RL.
For investors watching this space: the infrastructure play is maturing, the model race is compressing, and the application layer is getting thinner. The next durable positions will be carved out by products that own a specific user relationship — not by whoever has the best benchmark score this quarter.
We’ll keep hosting these sessions. The signal-to-noise ratio inside these conversations is meaningfully higher than what surfaces publicly.
<<< View All
Beyond DeepSeek: What China's Model Builders Are Seeing
<<< Back to All
3 of the top five most-popular models on OpenRouter’s LLM Ranking were developed by Chinese AI lab. Across the developer community, Chinese models have stopped being the “also-ran” story and started being the story.
We’ve been tracking China’s model ecosystem closely. After the Lunar New Year releases landed , Seedance 2.0(&Seed2.0), GLM-5, and MiniMax M2.5, we wanted to go beyond the benchmarks and the press releases. So we organized a closed-door discussion inside our Best Ideas community.
The session brought together a mix of voices: researchers from Zhipu, MiniMax, and ByteDance who are building these models, alongside developers and practitioners who are deploying them in production. What follows reflects the full conversation — not any single participant’s view.
Some of them confirmed what we expected. A lot of it didn’t.
This analysis and these judgments were compiled from a collective Best Ideas community discussion.
Seedance 2.0: For the first time, a Chinese model isn’t catching up — it’s leading
The framing that matters most about Seedance 2.0 isn’t technical — it’s historic. For the first time, a Chinese foundation model isn’t just competitive globally, it’s decisively ahead.
In video generation, the consensus in the room was that Seedance 2.0 stands at least a generation in front of Sora 2 and Veo 3. This isn’t a claim about catching up. It’s a claim about leading.
What makes that lead meaningful is where it lands: efficiency and usability, not just quality scores.
Seedance collapses the gap between idea and output in ways that restructure the economics of content creation entirely.
For non-professional creators, a full day of iteration compresses into thirty minutes. At that ratio, the traditional grammar of film and TV production, its workflows, budgets, and gatekeepers, doesn’t just become less relevant. It becomes a relic.
The room’s projection: within 6 to 12 months, for under $14, an ordinary person could plausibly produce a 30-40 minute film at Netflix-level image quality. The supply of content won’t just grow — it will compound.
The disruption runs in two directions:
- First, it is reshaping existing industries, film, games, advertising, where the cost structure of production is about to be repriced.
- Secondly, it is unlocking of scenarios that simply couldn’t exist before: real-time generated interactive video, AI companionship experiences, entirely new forms of social interaction built on personalized visual content.
Apprantly, the latter one looks more exciting to the community.
The shift from lottery to reliability is what makes this real. Older video models operated on what participants called a “roulette dynamic”: generate an eight-second clip, get three or four usable seconds, reroll. Seedance 2.0 broke that pattern. A single 15s-generation now largely meets commercial standards for semantic consistency and shot continuity — cinematic pacing, micro-expressions, the physical logic of how one shot leads into the next.
Video creation has moved from a roulette dynamic to something industrial-grade.
The discussion was direct about why ByteDance’s lead here is likely to persist. It’s not just compute or data. It’s organizational depth.
ByteDance appears to operate on what might be called a “three-generation” model cadence: one generation in live optimization, one in core development, and one in forward-looking research — a depth of parallel iteration that most peers, domestic and international, can barely sustain two of.
The downstream consequence that surprised us most: the teams under the most pressure right now aren’t incumbent video studios. It’s the workflow tool builders — the products that stitched together Midjourney for images, ElevenLabs for voice, and editing software into a chain. End-to-end models are quietly swallowing that stack.
MiniMax: The architecture is a commercial thesis, not a technical one
MiniMax M2’s parameter count — 200B total, 10B activated — is unusual enough that it raised eyebrows across the industry. The MiniMax team was direct about the reasoning: the sizing decision wasn’t a capability trade-off. It was a bet on how agents will actually be deployed.
In real agentic workflows, users run five to ten agents in parallel. Latency shapes productivity as much as raw capability. And as agents migrate from developers to mainstream users, they become 24/7 personal assistants — always-on, high-frequency, generating enormous token volumes.
At those usage densities, frontier pricing becomes structurally unsustainable. They pointed to Talkie — MiniMax’s companion AI product — as the proof of concept: wide audience, long conversation threads, extreme usage density. The M2-her model powering Talkie(MiniMax’s companion AI app) is a post-trained variant built on the M2 base.
The implicit critique of the broader industry is sharp: a model that tops every benchmark but prices itself out of agentic deployment isn’t winning the market. It’s winning a leaderboard.
MiniMax also shared the internal benchmark they built to evaluate the coding capability — VIBE Bench — which spans the full stack of real-world software development, including cloud configuration, multi-language environments, and API integrations.
Their view on standard benchmarks was pointed: SWE-style evaluations are too narrow (focused mostly on bug fixes) and too language-homogeneous (skewing Python and TypeScript, while production systems run Go, C++, Rust).
According to their internal testing, MiniMax M2 shows significant improvements over Claude Opus on the VIBE leaderboard.
The lesson the MiniMax team kept coming back to was Anthropic’s approach to dogfooding.
They’ve moved the entire company — including legal and HR — into an agent-native operating model. If agents fail at a task internally, that failure gets formalized as the next benchmark. It’s a feedback loop they believe is the actual reason Anthropic has been able to maintain both model depth and product quality — and where it genuinely leads most domestic players.
GLM-5: Benchmarking against Anthropic, not the leaderboard
There was an internal strategic debate at Zhipu AI that came up in the conversation. One path: chase top scores in math and coding competitions, optimize for reasoning benchmarks, build toward long-horizon scientific research. The other path: prioritize economically valuable productivity tasks — real-world programming workflows, agentic problem-solving.
Zhipu’s researchers chose the second, and chose Anthropic as the explicit benchmark.
The reasoning they laid out is worth unpacking. Coding and agent tasks aren’t just harder versions of reasoning tasks — they’re structurally different. Reasoning operates within a bounded problem space where heavy thinking, and reinforcement learning alone, can produce high scores. Complex coding requires something closer to engineering intuition: identifying root causes quickly, resolving issues with minimal token usage rather than trial and error. That kind of intuition, they found experimentally, scales with model size in ways that reasoning benchmarks don’t fully capture.
GLM-5 runs at 744B total parameters with roughly 40B activated per inference — deliberately constrained to fit within a standard 8-GPU cluster, keeping it viable for real-world production deployment. (Notably, GLM-5 was trained and runs inference entirely on Huawei Ascend chips, with no dependency on NVIDIA hardware — a geopolitical statement as much as a technical one.)
The model also introduces DSA (DeepSeek Sparse Attention) to handle long-context coding workloads, where input context regularly dwarfs generated output.
The competitive positioning Zhipu’s team laid out is explicit: Anthropic currently dominates the high end of the coding market at $15-25 per million tokens. GLM-5 is targeting the upper-middle segment at roughly $3 — a price gap significant enough that even developers deeply embedded in Claude’s tooling ecosystem are paying attention. Domestic open-source models have also maintained strong compatibility with Claude skills and related tooling, making switching relatively seamless.
What this means for the broader picture
A few things from the conversation that didn’t fit neatly into any single company’s story:
Data is becoming the real moat, not compute.
Multiple participants pointed to this independently. The paradigm is shifting from compute-bound to data-bound — not because compute isn’t scarce, but because it’s becoming more accessible. The edge increasingly lives in data acquisition, cleaning, long-tail mining, and evaluation loops. Seedance 2.0’s lead in video generation, for instance, is inseparable from fine-grained work on tail-end video data. And China has structural advantages here that are underappreciated: a deep ecosystem of small, agile video production teams capable of capturing proprietary footage at scale.
Hardware scarcity is driving architecture-level innovation.
Chinese companies are working under tighter GPU constraints than their Silicon Valley counterparts. Several researchers noted that this is producing more architectural creativity at the inference layer — necessity forcing efficiency work that well-resourced labs have little incentive to do.
The market won’t consolidate to one winner.
The consensus in the room was that the AI market will look less like search (9:1 winner-take-all) and more like e-commerce — multiple players finding durable niches through different product sensibilities and user relationships. When model capabilities converge, the differentiation shifts to taste: do you build a maximally efficient tool, or a product with genuine personality?
The question we’re sitting with
We framed 2026 as a structural inflection point, not an incremental one. The Lunar New Year releases were the opening move. By mid-year, new long-horizon reasoning models and async agent frameworks are expected to enter. Every industry is showing up with real deployment use cases.
The harder question — one the room didn’t fully resolve — is what happens to the application layer. Agent capabilities are increasingly being driven by base model improvements, which means orchestration logic and system prompt design that once belonged to application developers is getting absorbed into the model itself. Kimi 2.5 reportedly baked an orchestrator-plus-subagent architecture directly into the model via RL.
For investors watching this space: the infrastructure play is maturing, the model race is compressing, and the application layer is getting thinner. The next durable positions will be carved out by products that own a specific user relationship — not by whoever has the best benchmark score this quarter.
We’ll keep hosting these sessions. The signal-to-noise ratio inside these conversations is meaningfully higher than what surfaces publicly.
Beyond DeepSeek: What China's Model Builders Are Seeing
<<< Back to All
3 of the top five most-popular models on OpenRouter’s LLM Ranking were developed by Chinese AI lab. Across the developer community, Chinese models have stopped being the “also-ran” story and started being the story.
We’ve been tracking China’s model ecosystem closely. After the Lunar New Year releases landed , Seedance 2.0(&Seed2.0), GLM-5, and MiniMax M2.5, we wanted to go beyond the benchmarks and the press releases. So we organized a closed-door discussion inside our Best Ideas community.
The session brought together a mix of voices: researchers from Zhipu, MiniMax, and ByteDance who are building these models, alongside developers and practitioners who are deploying them in production. What follows reflects the full conversation — not any single participant’s view.
Some of them confirmed what we expected. A lot of it didn’t.
This analysis and these judgments were compiled from a collective Best Ideas community discussion.
Seedance 2.0: For the first time, a Chinese model isn’t catching up — it’s leading
The framing that matters most about Seedance 2.0 isn’t technical — it’s historic. For the first time, a Chinese foundation model isn’t just competitive globally, it’s decisively ahead.
In video generation, the consensus in the room was that Seedance 2.0 stands at least a generation in front of Sora 2 and Veo 3. This isn’t a claim about catching up. It’s a claim about leading.
What makes that lead meaningful is where it lands: efficiency and usability, not just quality scores.
Seedance collapses the gap between idea and output in ways that restructure the economics of content creation entirely.
For non-professional creators, a full day of iteration compresses into thirty minutes. At that ratio, the traditional grammar of film and TV production, its workflows, budgets, and gatekeepers, doesn’t just become less relevant. It becomes a relic.
The room’s projection: within 6 to 12 months, for under $14, an ordinary person could plausibly produce a 30-40 minute film at Netflix-level image quality. The supply of content won’t just grow — it will compound.
The disruption runs in two directions:
- First, it is reshaping existing industries, film, games, advertising, where the cost structure of production is about to be repriced.
- Secondly, it is unlocking of scenarios that simply couldn’t exist before: real-time generated interactive video, AI companionship experiences, entirely new forms of social interaction built on personalized visual content.
Apprantly, the latter one looks more exciting to the community.
The shift from lottery to reliability is what makes this real. Older video models operated on what participants called a “roulette dynamic”: generate an eight-second clip, get three or four usable seconds, reroll. Seedance 2.0 broke that pattern. A single 15s-generation now largely meets commercial standards for semantic consistency and shot continuity — cinematic pacing, micro-expressions, the physical logic of how one shot leads into the next.
Video creation has moved from a roulette dynamic to something industrial-grade.
The discussion was direct about why ByteDance’s lead here is likely to persist. It’s not just compute or data. It’s organizational depth.
ByteDance appears to operate on what might be called a “three-generation” model cadence: one generation in live optimization, one in core development, and one in forward-looking research — a depth of parallel iteration that most peers, domestic and international, can barely sustain two of.
The downstream consequence that surprised us most: the teams under the most pressure right now aren’t incumbent video studios. It’s the workflow tool builders — the products that stitched together Midjourney for images, ElevenLabs for voice, and editing software into a chain. End-to-end models are quietly swallowing that stack.
MiniMax: The architecture is a commercial thesis, not a technical one
MiniMax M2’s parameter count — 200B total, 10B activated — is unusual enough that it raised eyebrows across the industry. The MiniMax team was direct about the reasoning: the sizing decision wasn’t a capability trade-off. It was a bet on how agents will actually be deployed.
In real agentic workflows, users run five to ten agents in parallel. Latency shapes productivity as much as raw capability. And as agents migrate from developers to mainstream users, they become 24/7 personal assistants — always-on, high-frequency, generating enormous token volumes.
At those usage densities, frontier pricing becomes structurally unsustainable. They pointed to Talkie — MiniMax’s companion AI product — as the proof of concept: wide audience, long conversation threads, extreme usage density. The M2-her model powering Talkie(MiniMax’s companion AI app) is a post-trained variant built on the M2 base.
The implicit critique of the broader industry is sharp: a model that tops every benchmark but prices itself out of agentic deployment isn’t winning the market. It’s winning a leaderboard.
MiniMax also shared the internal benchmark they built to evaluate the coding capability — VIBE Bench — which spans the full stack of real-world software development, including cloud configuration, multi-language environments, and API integrations.
Their view on standard benchmarks was pointed: SWE-style evaluations are too narrow (focused mostly on bug fixes) and too language-homogeneous (skewing Python and TypeScript, while production systems run Go, C++, Rust).
According to their internal testing, MiniMax M2 shows significant improvements over Claude Opus on the VIBE leaderboard.
The lesson the MiniMax team kept coming back to was Anthropic’s approach to dogfooding.
They’ve moved the entire company — including legal and HR — into an agent-native operating model. If agents fail at a task internally, that failure gets formalized as the next benchmark. It’s a feedback loop they believe is the actual reason Anthropic has been able to maintain both model depth and product quality — and where it genuinely leads most domestic players.
GLM-5: Benchmarking against Anthropic, not the leaderboard
There was an internal strategic debate at Zhipu AI that came up in the conversation. One path: chase top scores in math and coding competitions, optimize for reasoning benchmarks, build toward long-horizon scientific research. The other path: prioritize economically valuable productivity tasks — real-world programming workflows, agentic problem-solving.
Zhipu’s researchers chose the second, and chose Anthropic as the explicit benchmark.
The reasoning they laid out is worth unpacking. Coding and agent tasks aren’t just harder versions of reasoning tasks — they’re structurally different. Reasoning operates within a bounded problem space where heavy thinking, and reinforcement learning alone, can produce high scores. Complex coding requires something closer to engineering intuition: identifying root causes quickly, resolving issues with minimal token usage rather than trial and error. That kind of intuition, they found experimentally, scales with model size in ways that reasoning benchmarks don’t fully capture.
GLM-5 runs at 744B total parameters with roughly 40B activated per inference — deliberately constrained to fit within a standard 8-GPU cluster, keeping it viable for real-world production deployment. (Notably, GLM-5 was trained and runs inference entirely on Huawei Ascend chips, with no dependency on NVIDIA hardware — a geopolitical statement as much as a technical one.)
The model also introduces DSA (DeepSeek Sparse Attention) to handle long-context coding workloads, where input context regularly dwarfs generated output.
The competitive positioning Zhipu’s team laid out is explicit: Anthropic currently dominates the high end of the coding market at $15-25 per million tokens. GLM-5 is targeting the upper-middle segment at roughly $3 — a price gap significant enough that even developers deeply embedded in Claude’s tooling ecosystem are paying attention. Domestic open-source models have also maintained strong compatibility with Claude skills and related tooling, making switching relatively seamless.
What this means for the broader picture
A few things from the conversation that didn’t fit neatly into any single company’s story:
Data is becoming the real moat, not compute.
Multiple participants pointed to this independently. The paradigm is shifting from compute-bound to data-bound — not because compute isn’t scarce, but because it’s becoming more accessible. The edge increasingly lives in data acquisition, cleaning, long-tail mining, and evaluation loops. Seedance 2.0’s lead in video generation, for instance, is inseparable from fine-grained work on tail-end video data. And China has structural advantages here that are underappreciated: a deep ecosystem of small, agile video production teams capable of capturing proprietary footage at scale.
Hardware scarcity is driving architecture-level innovation.
Chinese companies are working under tighter GPU constraints than their Silicon Valley counterparts. Several researchers noted that this is producing more architectural creativity at the inference layer — necessity forcing efficiency work that well-resourced labs have little incentive to do.
The market won’t consolidate to one winner.
The consensus in the room was that the AI market will look less like search (9:1 winner-take-all) and more like e-commerce — multiple players finding durable niches through different product sensibilities and user relationships. When model capabilities converge, the differentiation shifts to taste: do you build a maximally efficient tool, or a product with genuine personality?
The question we’re sitting with
We framed 2026 as a structural inflection point, not an incremental one. The Lunar New Year releases were the opening move. By mid-year, new long-horizon reasoning models and async agent frameworks are expected to enter. Every industry is showing up with real deployment use cases.
The harder question — one the room didn’t fully resolve — is what happens to the application layer. Agent capabilities are increasingly being driven by base model improvements, which means orchestration logic and system prompt design that once belonged to application developers is getting absorbed into the model itself. Kimi 2.5 reportedly baked an orchestrator-plus-subagent architecture directly into the model via RL.
For investors watching this space: the infrastructure play is maturing, the model race is compressing, and the application layer is getting thinner. The next durable positions will be carved out by products that own a specific user relationship — not by whoever has the best benchmark score this quarter.
We’ll keep hosting these sessions. The signal-to-noise ratio inside these conversations is meaningfully higher than what surfaces publicly.